Large Language Models (LLMs) such as GPT-4 and Claude are remarkable, but fluency creates inflated expectations. Myths spread quickly, often detached from research. Misunderstanding these systems leads to misuse and misplaced trust.
At Hudson Labs, we are bullish on AI — but we believe the real breakthroughs will come from specialized systems, not one-size-fits-all chatbots. That’s why we examine common myths and test them against evidence.
Myth 1: LLMs can pick stocks
Some investors expect LLMs to outperform the market.
Fact
Some investors expect LLMs to outperform the market.
Fact: Sure, short-term sentiment signals are real (e.g. Lopez-Lira & Tang, 2023) and LLMs even show some ability to incorporate fundamentals and macro data (Fatouros et al., 2024 just 100 stocks over 15 months).
However, over the long term and a broader universe, LLM strategies can’t beat passive benchmarks consistently, are regime-fragile, and lack domain-aware financial logic (Li et al.; 2025). And in practice, confirmation-farming — nudging the model until it echoes your bias — remains a real risk (Sun & Kok, Jun, 2025; Wan et al., Jun 2025).
LLM reasoning abilities are severely over-estimated.
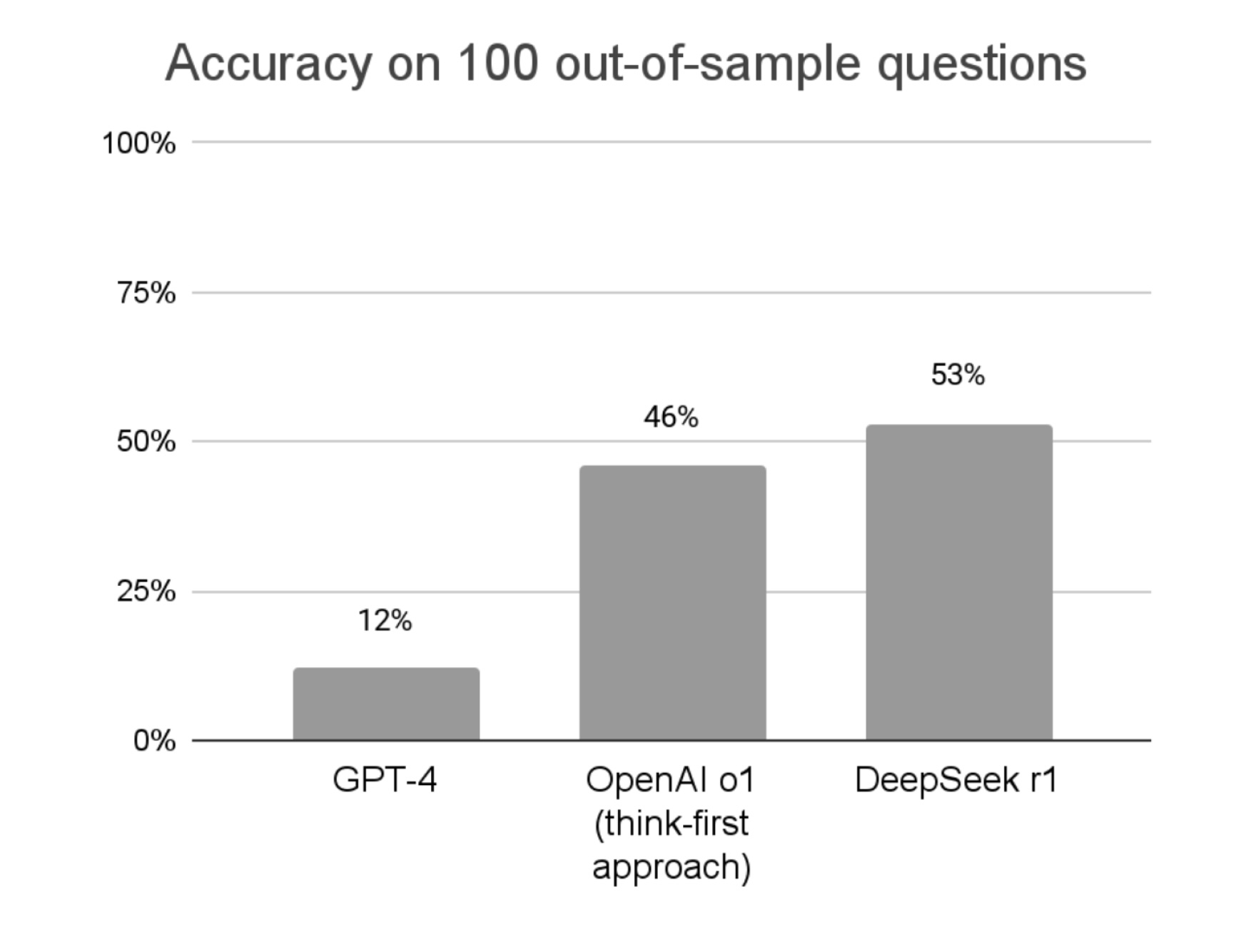
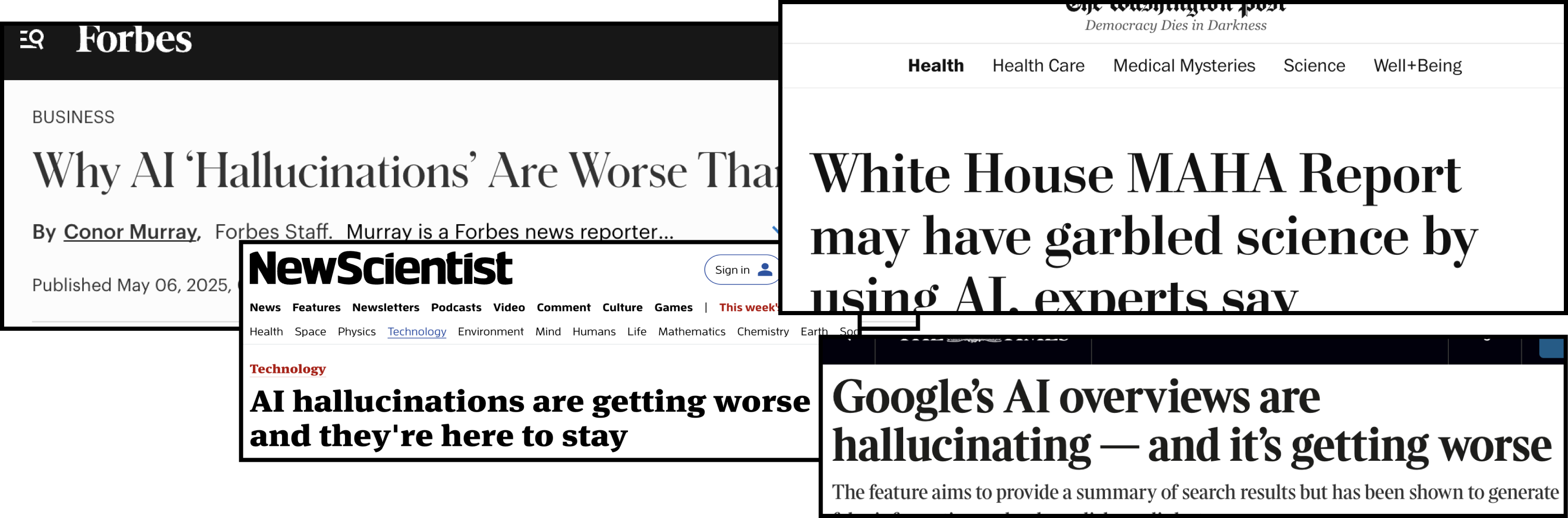
Myth 2: Hallucinations are a thing of the past
Vendors imply that newer models have solved hallucinations.
Fact
Hallucinations persist and, in some cases, grow worse. As models become more fluent, fabricated statements sound more convincing (Maynez et al., 2020; Ji et al., 2023). Errors are harder, not easier, to detect.
Institutional investors managing millions cannot rely on generalist AI that fabricates data. The Co-Analyst reduces hallucinations through confidence-based decoding and rigorous post-processing — and when information is unavailable, it returns ‘N/A’ rather than inventing results.
Myth 3: There is a secret system prompt
Some believe a hidden instruction unlocks new intelligence.
Fact
Hacking a system prompt does not unlock new abilities. Prompts can change style or bypass safeguards, but they cannot expand competence. Model capabilities are set by training and architecture (Zou et al., 2023).
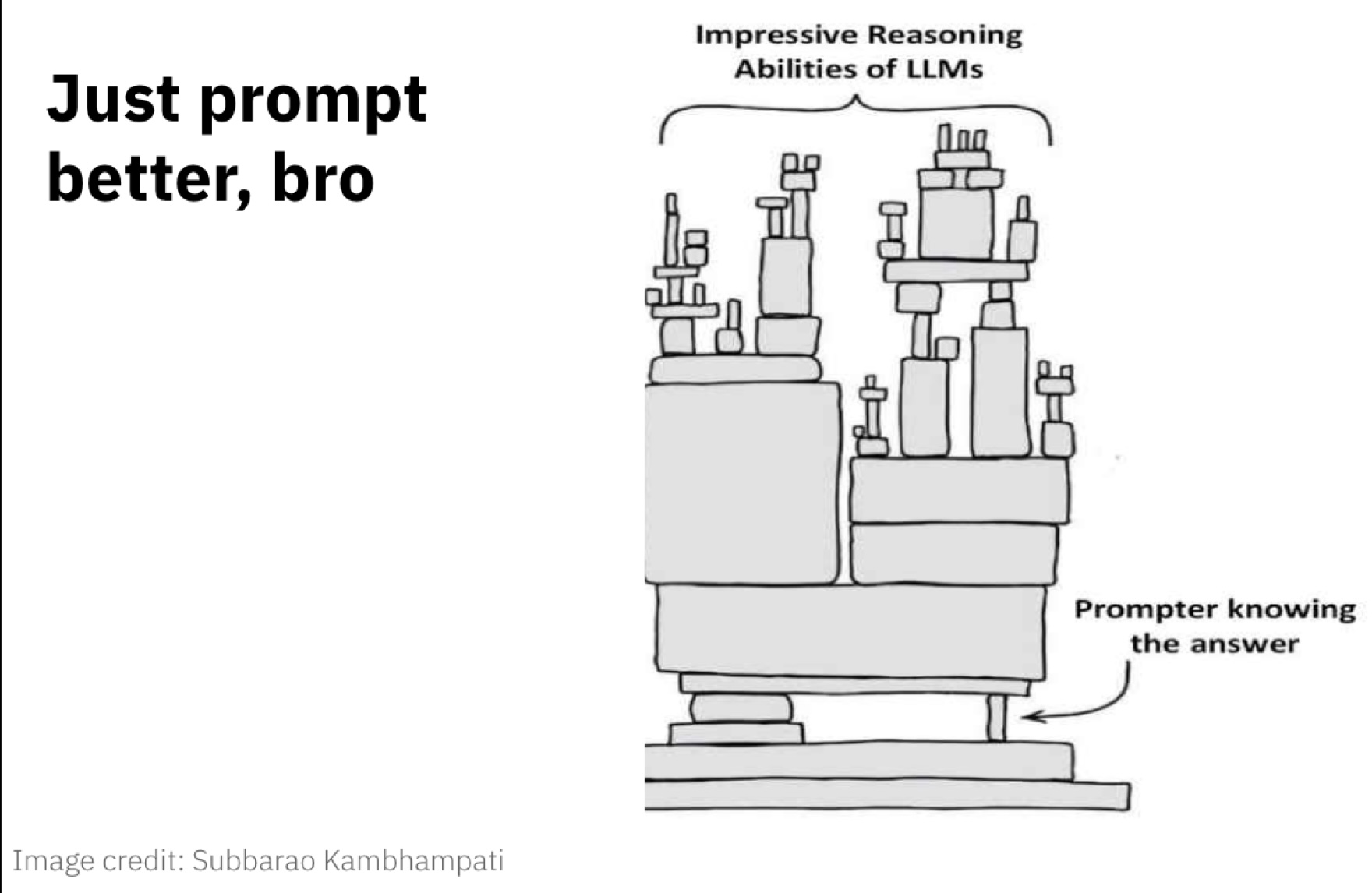
Myth 4: The more an LLM “thinks,” the better the results
It seems natural to assume that more reasoning produces better answers.
Fact
When a model rethinks too much, it often overrides correct answers with incorrect ones. Research shows long reasoning chains can reduce accuracy (Turpin et al., 2023). Chain-of-thought prompting helps in arithmetic (Wei et al., 2022) but can harm factual recall.

Myth 5: Reasoning traces are faithful explanations
Models sometimes display “thoughts” or traces of reasoning.
Fact
These traces are not windows into model cognition. They are generated text, optimized for plausibility. They do not reveal how the model works (Turpin et al., 2023; Lanham et al., 2023).

Myth 6: Six-page prompts give better results
Some users build long prompts filled with examples and constraints.
Fact
Even the most sophisticated models cannot track that many instructions. Overly long prompts confuse them, leading to worse performance (Liu et al., 2023). Clear, direct prompts outperform sprawling scripts.

Myth 7: A five-day course on prompt engineering will transform your AI experience
Courses promise mastery through long lists of tricks.
Fact
Over-prompting can backfire. Each new instruction risks displacing another, and more prompts rarely improve performance (Ganguli et al., 2022). In practice, users can fall into “confirmation-farming,” nudging the model to echo their own preferences. Effective prompting is about balance, experimentation, and knowing which instructions truly matter.
Conclusion
LLMs are powerful but limited. They hallucinate, misreason, and lose track of long instructions. They cannot pick stocks or explain their reasoning. For investment research, you need more than a general-purpose chatbot.
At Hudson Labs, we are bullish on AI. The breakthroughs of the past few years prove that these systems can transform industries. But we believe the future lies not in generalist AI that tries to do everything, but in specialized AI built for high-stakes domains.
Generalist models struggle where investors need the most precision: analyzing multiple periods across long documents, interpreting forward-looking statements and guidance, and maintaining numeric accuracy. That’s why we built the Co-Analyst: a specialized system with proprietary retrieval, custom AI models, agentic source selection, and in-house pipelines designed for accuracy.
Where generic LLMs generate fluent guesses, the Co-Analyst delivers accuracy, transparency, and efficiency. We see specialized AI not as a limitation, but as the most powerful way to unlock AI’s true potential in finance.
Start your trial to learn how the Co-Analyst can transform your investment research workflow.
References and Key Findings
Ganguli, D., Askell, A., et al. (2022). Red Teaming Language Models with Language Models. → Demonstrates how LLMs can be manipulated into harmful outputs, underscoring trade-offs in adding instructions.
Ji, Z., Lee, N., Frieske, R., et al. (2023). Survey of Hallucination in Natural Language Generation. → Reviews hallucination across tasks, showing that more fluent models often make errors harder to spot.
Lanham, J., et al. (2023). Measuring Faithfulness in Chain-of-Thought Reasoning. → Finds that reasoning traces often look plausible but are not faithful explanations of internal computation.
Liu, N., et al. (2023). Evaluating Long Instruction Prompts for Large Language Models. → Shows diminishing returns from long prompts; overly complex instructions reduce accuracy.
Lopez-Lira, A., & Tang, Y. (2023). Can ChatGPT Forecast Stock Price Movements? → Finds weak predictive ability and heavy dependence on prompt framing; models often echo user bias.
Maynez, J., Narayan, S., Bohnet, B., & McDonald, R. (2020). On Faithfulness and Factuality in Abstractive Summarization. → Shows that fluent summaries can be factually incorrect, a core form of hallucination.
Turpin, M., et al. (2023). Language Models Don’t Always Need to Think Step-By-Step. → Finds that longer reasoning chains sometimes reduce accuracy, especially in factual questions.
Wei, J., et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. → Introduces chain-of-thought prompting, showing gains on reasoning-heavy tasks like math and logic.
Zou, A., et al. (2023). Universal and Transferable Adversarial Attacks on Aligned Language Models. → Demonstrates that jailbreak prompts bypass safeguards but do not create new model capabilities.


