We compare the Hudson Labs Co-Analyst to GPT-4o in the analysis below. The results demonstrate that Hudson Labs consistently outperforms GPT-4o in investor-specific workflows—particularly in guidance extraction, numeric accuracy, and multi-period document analysis.
We do not claim general AI superiority—only targeted outperformance in investor-specific workflows. For creative tasks such as writing and style transfer, OpenAI models and other offerings from the big labs will be better suited. Also see comparisons of the Co-Analyst to OpenAI's o3 and Perplexity.
Most financial AI tools are OpenAI wrappers
Many, if not most, finance-specific applications, including well-known brands, implement a wrapper on top of OpenAI. While this approach performs well for general tasks, its failure modes impact usability, particularly in financial workflows.
To be clear, this is not a critique of OpenAI’s model quality—on many general-purpose tasks, they outperform competitors. Hudson Labs, in fact, uses OpenAI models for select sub-tasks within the Co-Analyst. However, our architecture incorporates more than five other LLMs along with proprietary retrieval, source selection, and pre- and post-processing pipelines.
Our comparison to GPT-4o illustrates the differences between the Hudson Labs Co-Analyst and generalist systems (often OpenAI wrappers), which constitute most of the financial AI software on the market today.
Where the Hudson Labs Co-Analyst Excels:
Multi-period document analysis
The Co-Analyst excels when analyzing multiple long-form documents, such as earnings calls spanning more than four quarters. Its proprietary retrieval system scales better than generalist alternatives.
Guidance identification
Guidance often requires interpreting subtle context—sometimes from previous sentences or adjacent paragraphs. Our multi-model architecture ensures accurate extraction, even across periods.
Reliable results
Unlike other tools, Hudson Labs only generates answers using information from source, not model memory. The Co-Analyst minimizes hallucination through confidence-based decoding and post-processing. When information is unavailable, it returns “N/A” rather than fabricating results.
Numeric focus
Many AI systems provide general commentary but omit key figures. The Co-Analyst prioritizes numeric specificity and precision.
Under-covered names
Unlike models reliant on web search, the Co-Analyst maintains performance across the cap spectrum—from micro caps to mega caps.
The evaluation below tests the investor-specific areas where Hudson Labs specializes.
The Hudson Labs Co-Analyst compared to GPT-4o
Executive Summary
We evaluate GPT-4o across two modalities: Web and Uploads. In the first test, GPT-4o uses web search. Nearly every response contains a critical error—missing information, incorrect results, or hallucination.
Our second test assumes the AI application chooses the correct source documents (uploads) at inference time*. GPT-4o achieved a 50 percent success rate when the correct sources are uploaded.
In comparison, the Hudson Labs Co-Analyst achieved 100% completeness, precision and accuracy. More importantly, the Co-Analyst required no prompt engineering, and no queries had to be retried.
*In most financial AI applications, the assumption that source selection will be accurate is not valid because this is a complicated technical problem.
Methodology
We compare the Co-Analyst to GPT-4o using targeted queries that reflect Hudson Labs’ core strengths: multi-period analysis, guidance extraction, numeric precision, and reliability.
Tests
1. Steve Madden China sourcing exposure
GPT-4o - web
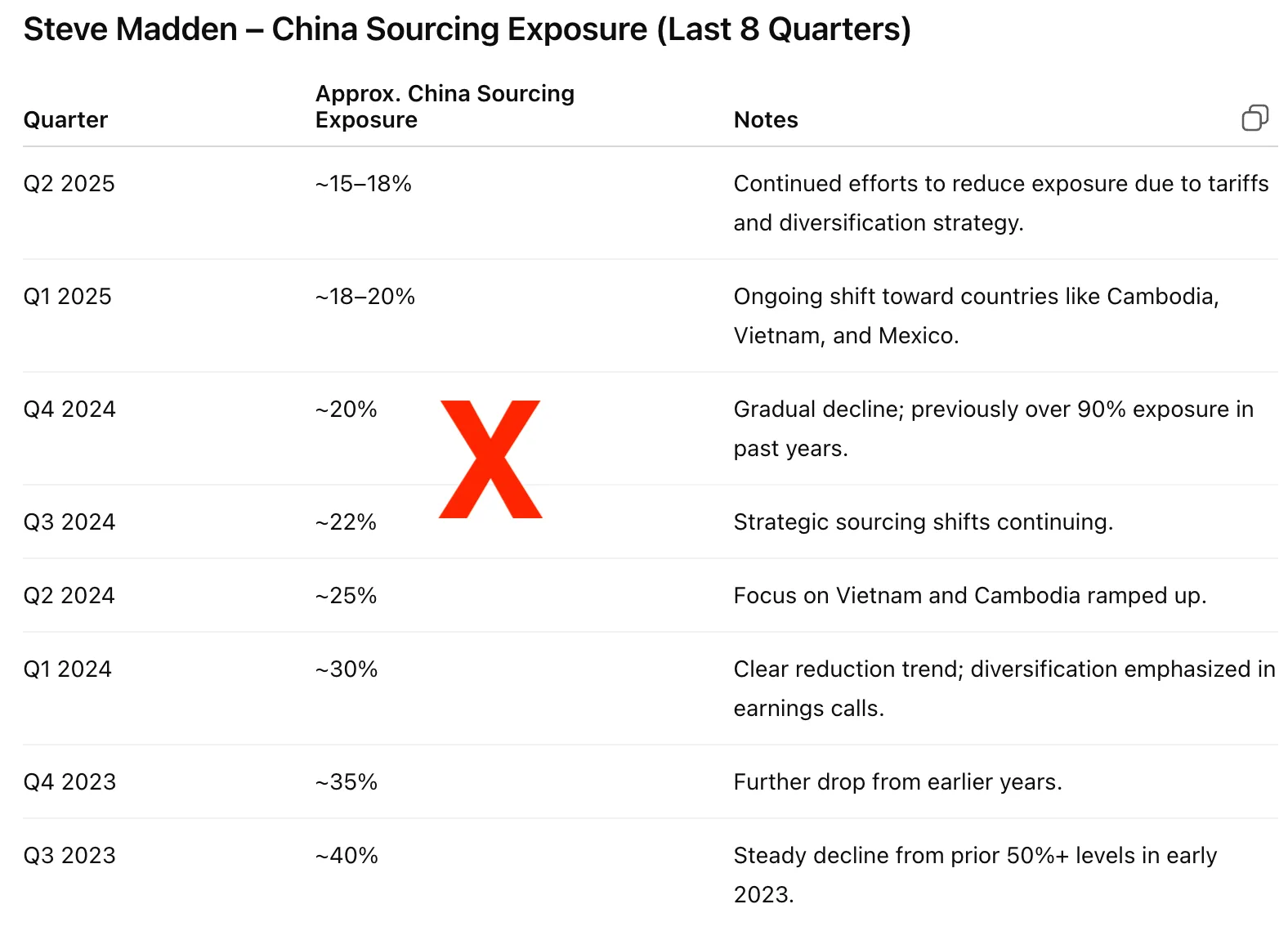
GPT-4o correctly identified figures for only 2 of 8 quarters and hallucinated the rest. Across five retries, results varied widely and lacked citation.

We tried this query multiple times. See the first attempt here. On attempt two, GPT-4o provided answers ranging from 15% in the most recent quarter to 40% in Q3 2023 (see image below).On the third attempt, GPT-4o provided figures ranging from 20-35%. On the fourth attempt, numbers ranging from 60-85%. These figures are uncited and their origin could not be determined. The fifth attempt was similar to the first.
GPT-4o - uploads
GPT-4o failed to extract figures in the first attempt, returning only qualitative commentary. In the second attempt, it returned hallucinated numbers. We provided GPT-4o with PDF versions of Steve Madden’s earnings releases and call transcripts for the past 4 quarters for both attempts.
A more explicit prompt led to fabricated figures (83% for all quarters). See both results here.

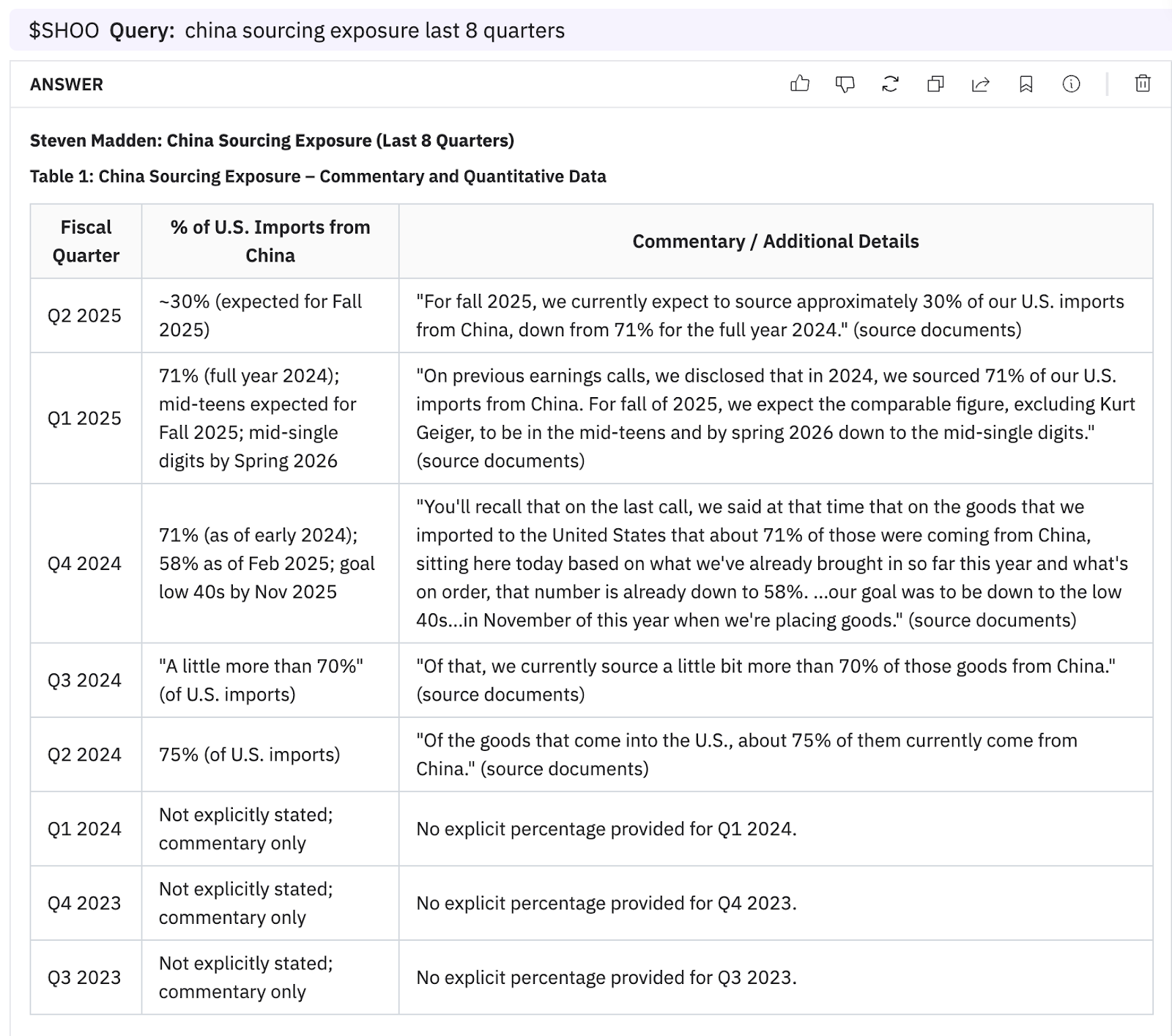
Hudson Labs Co-Analyst
The Co-Analyst delivered precise, cited figures with no hallucination and returned “N/A” where data was absent. See the full Co-Analyst result here.
2. Apple revenue breakdown by segment
GPT-4o - web
GPT-4o + web skipped the Q4 2024 quarter entirely and was only able to provide the breakdown (by product category) for the most recent two quarters (Q2 and Q1 2025). Apple's reportable business segments are technically based on geography, not product. Apple reports revenue for its segments under the heading "Net sales by reportable segment" in the earnings release. Find the full GPT- 4o results here.

GPT-4o - uploads
GPT-4o was able to provide the breakdown for 4 quarters successfully. However, we were unable to obtain unrounded figures. GPT-4o was provided with 4 quarters of earnings releases and earnings call transcripts in PDF format. We were unable to test uploading 8 quarters due to length restrictions. See the full GPT-4o results here.
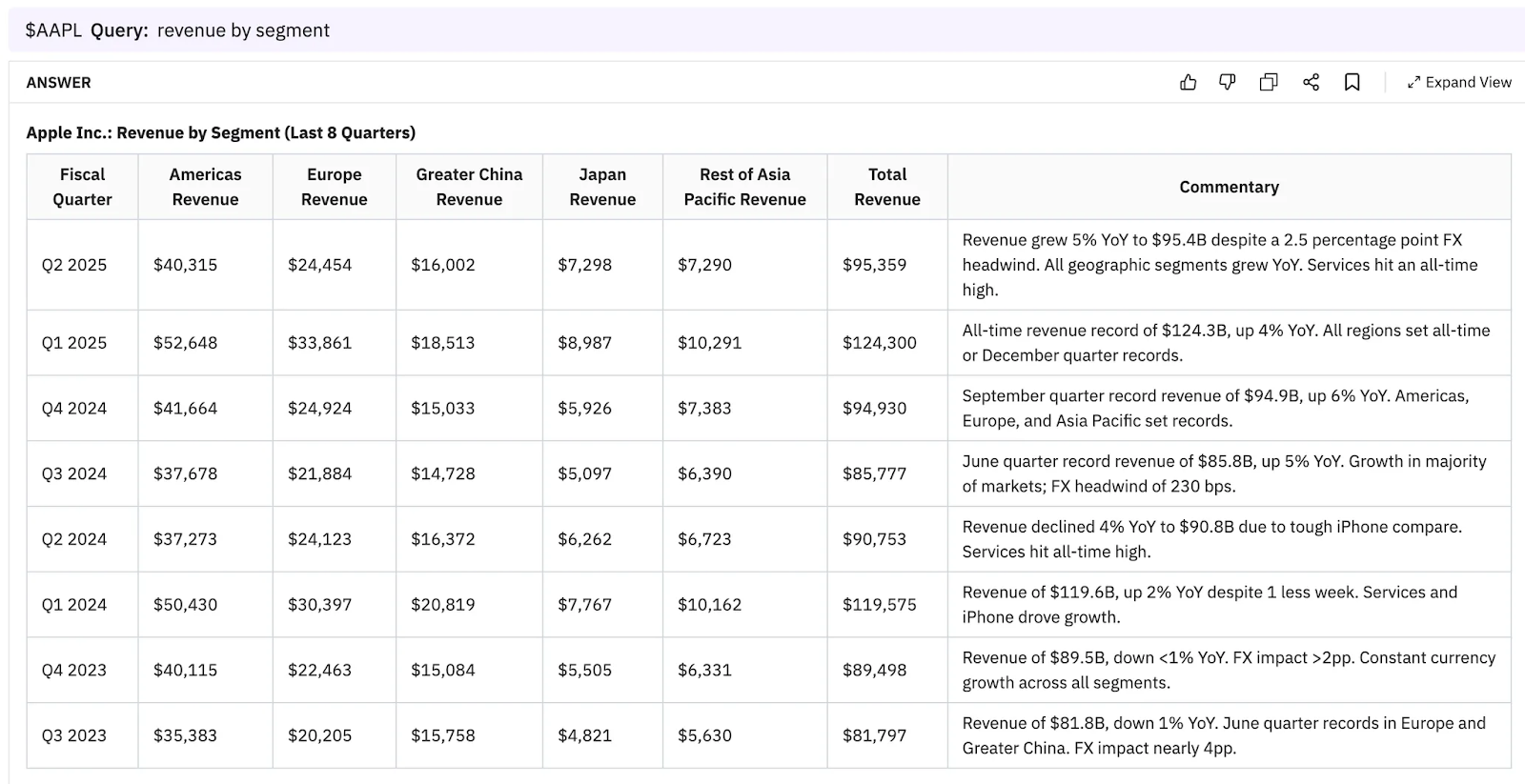
Hudson Labs Co-Analyst
The Co-Analyst provided complete, accurate and precise results, incorporating figures from the press release and commentary from the calls for the full 8 quarters. See the Co-Analyst results for "revenue by segment" for all 8 quarters here. See the results for "revenue by product" here.
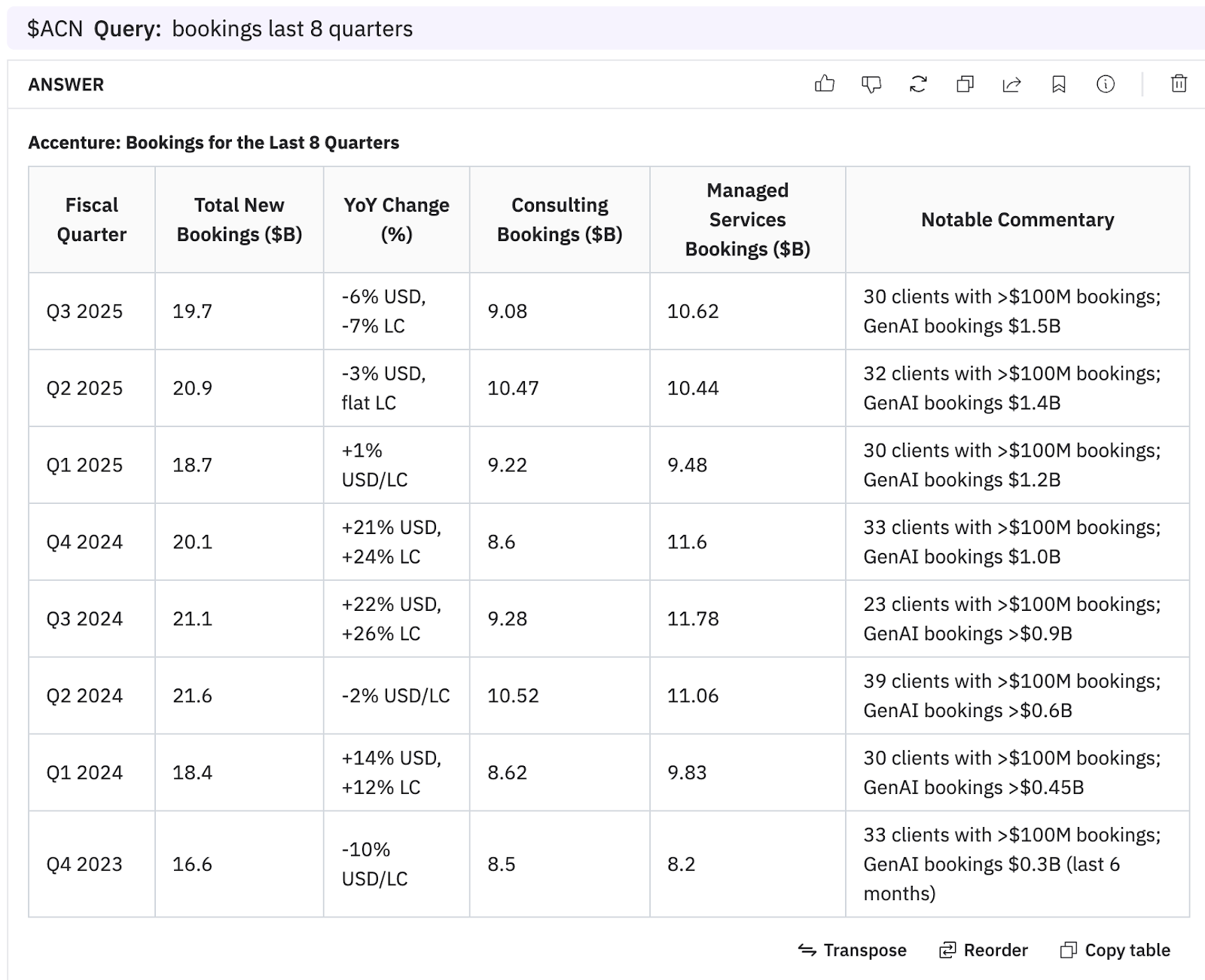
3. Accenture bookings trends
GPT-4o - web
GPT-4o + web provided total new bookings figures for the most recent 4 quarters, instead of 8. The 4 most recent totals were correct. When asked for the breakdown of bookings by type of work, GPT-4o only provided the breakdown for select quarters: Q3 2025, Q4 2024, and Q4 2023. See the full results here.
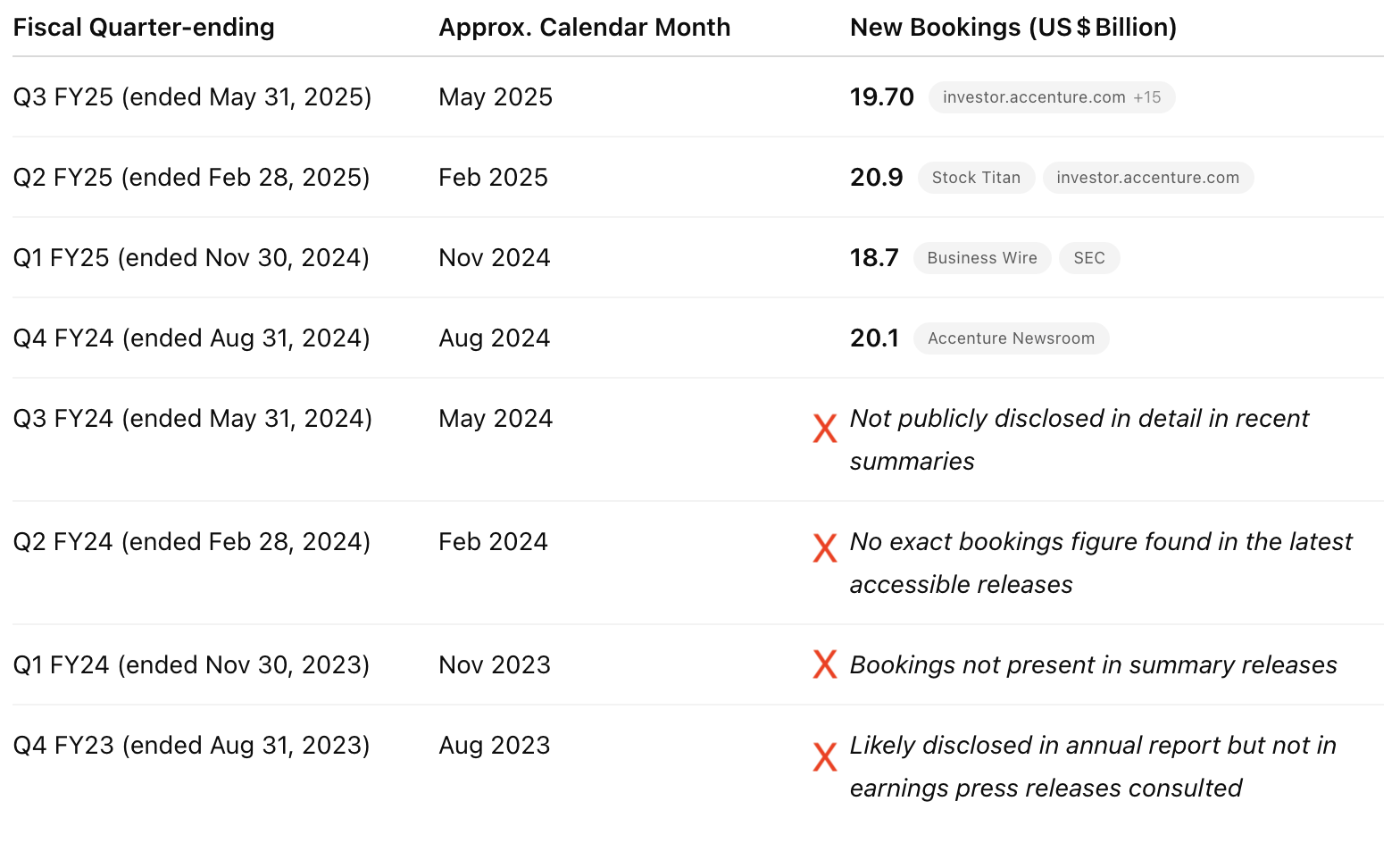
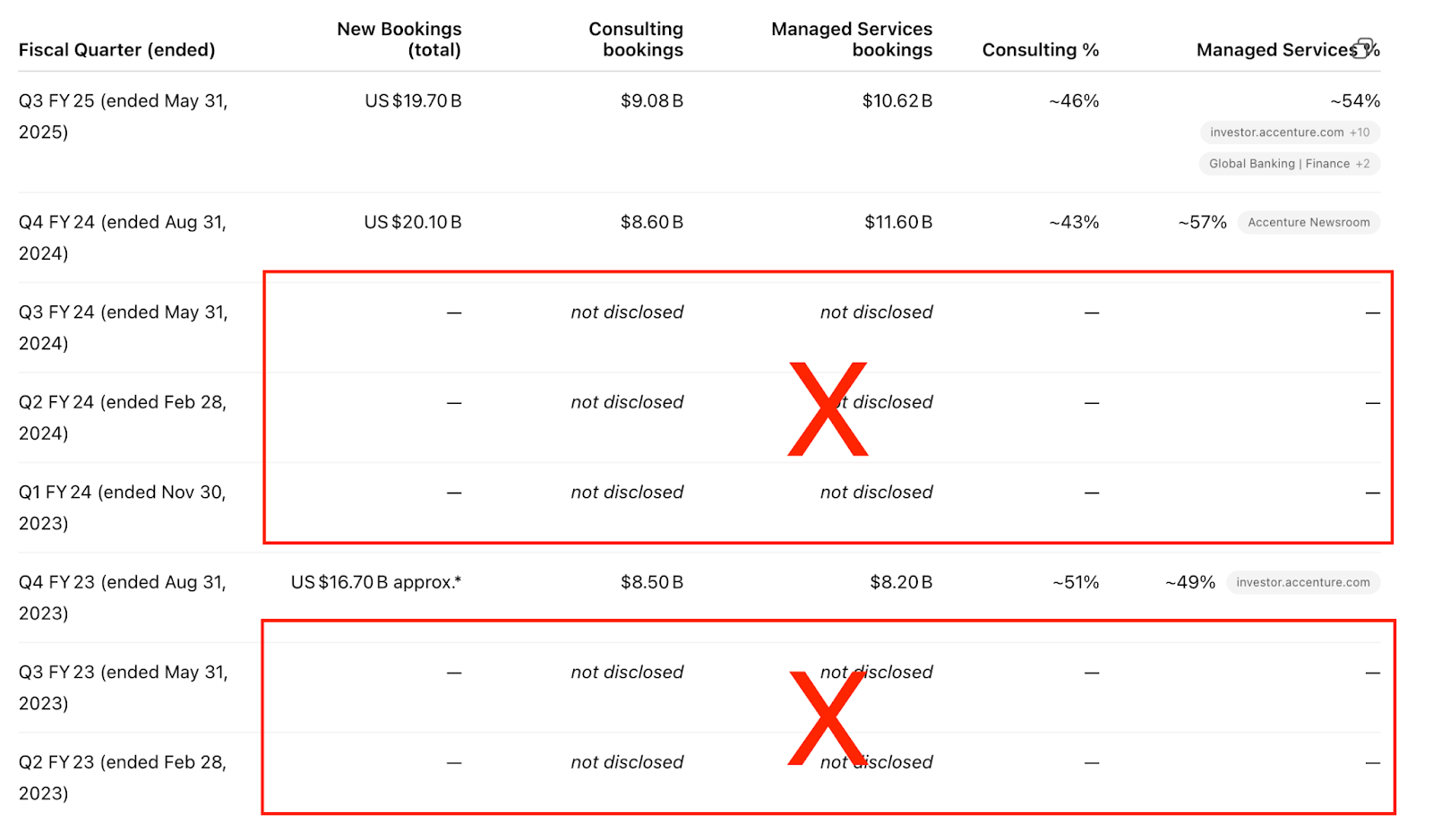
GPT-4o - uploads
GPT-4o provided the correct results for the last 4 quarters. We were unable to test 8 quarters due to length restrictions. We uploaded earnings releases and earnings call transcripts for the past 4 quarters in PDF format. See the results here.
Hudson Labs Co-Analyst
The Co-Analyst provides detailed and precise bookings data for all 8 quarters, as seen here.
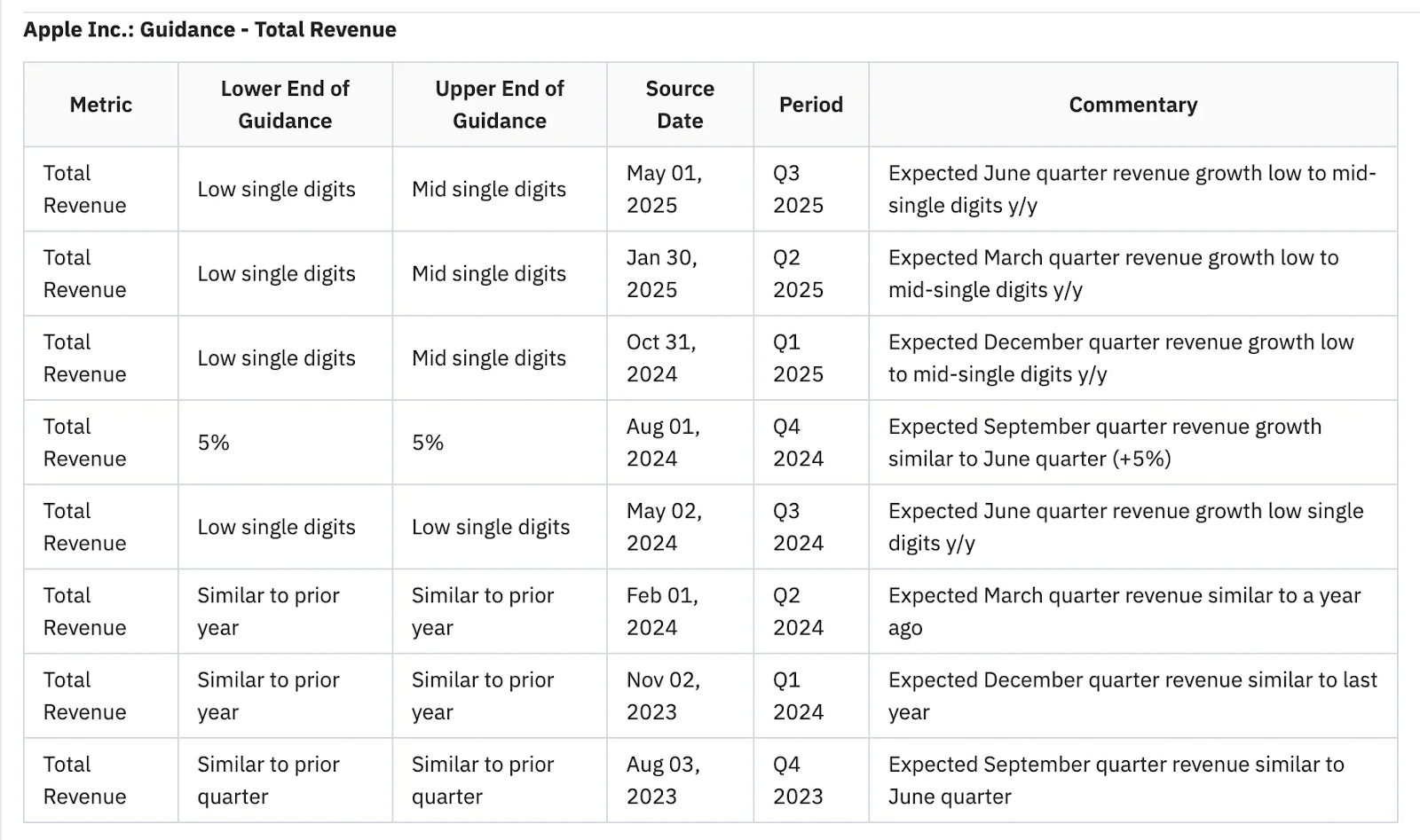
4. Apple revenue guidance over time
GPT-4o - web
GPT-4o was unable to provide the revenue guidance for the most recent quarter (Q2 2025) and incorrectly reported that Apple did not provide guidance during this call. It did correctly extract revenue guidance for two previous quarters. See the results here.
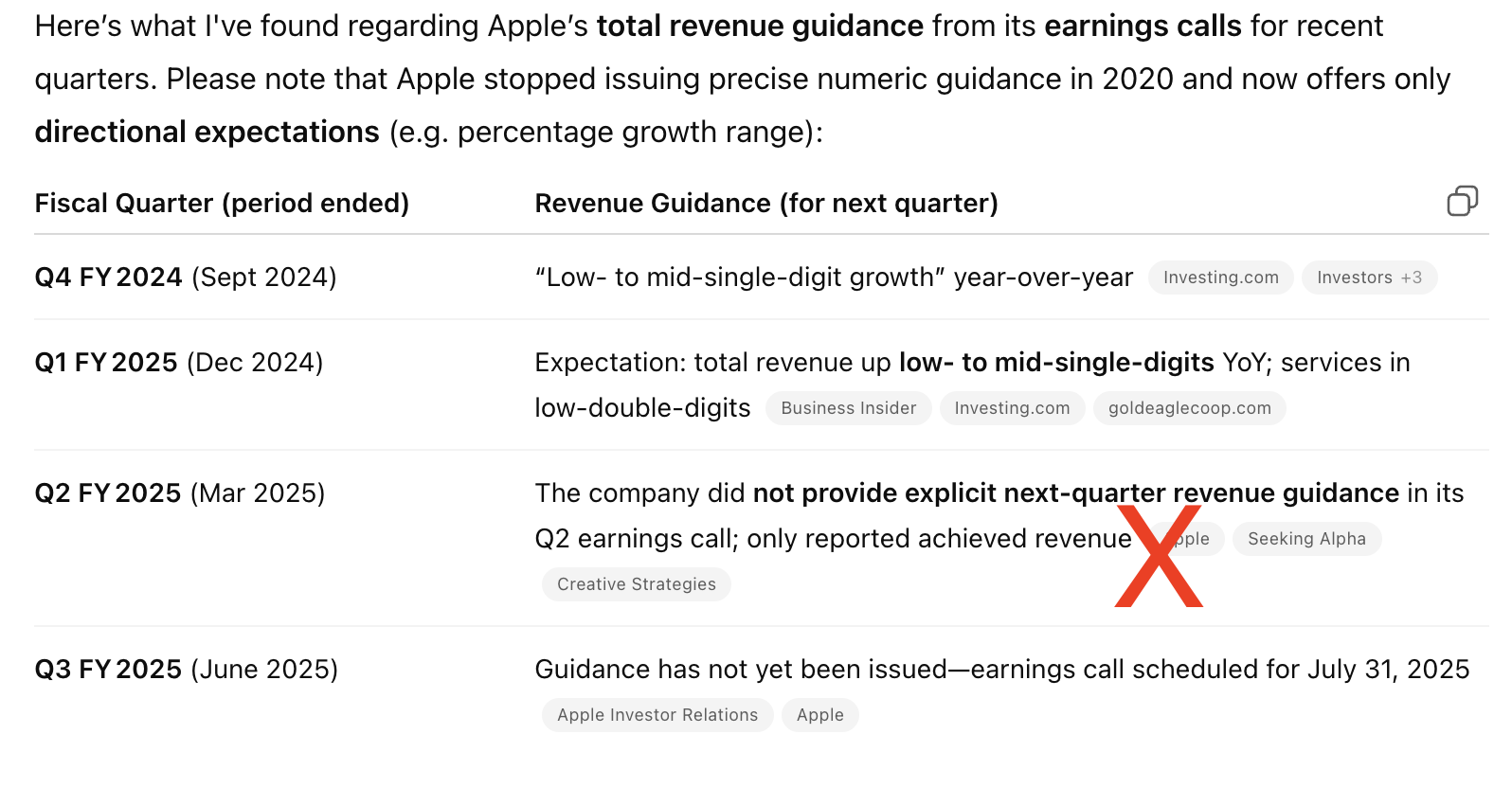

GPT-4o - uploads
We provided GPT-4o with access to the source PDFs (calls and press releases) for the past 4 quarters. GPT-4o reported actual revenue instead of guidance, failing to differentiate between the two.
We retried with a more specific prompt but got actuals in lieu of guidance. In both cases, GPT-4o returned actuals rather than guidance, despite the prompt. The table below shows the reported revenue and revenue growth—misleading results when guidance was requested. See the results for both queries with uploads here.
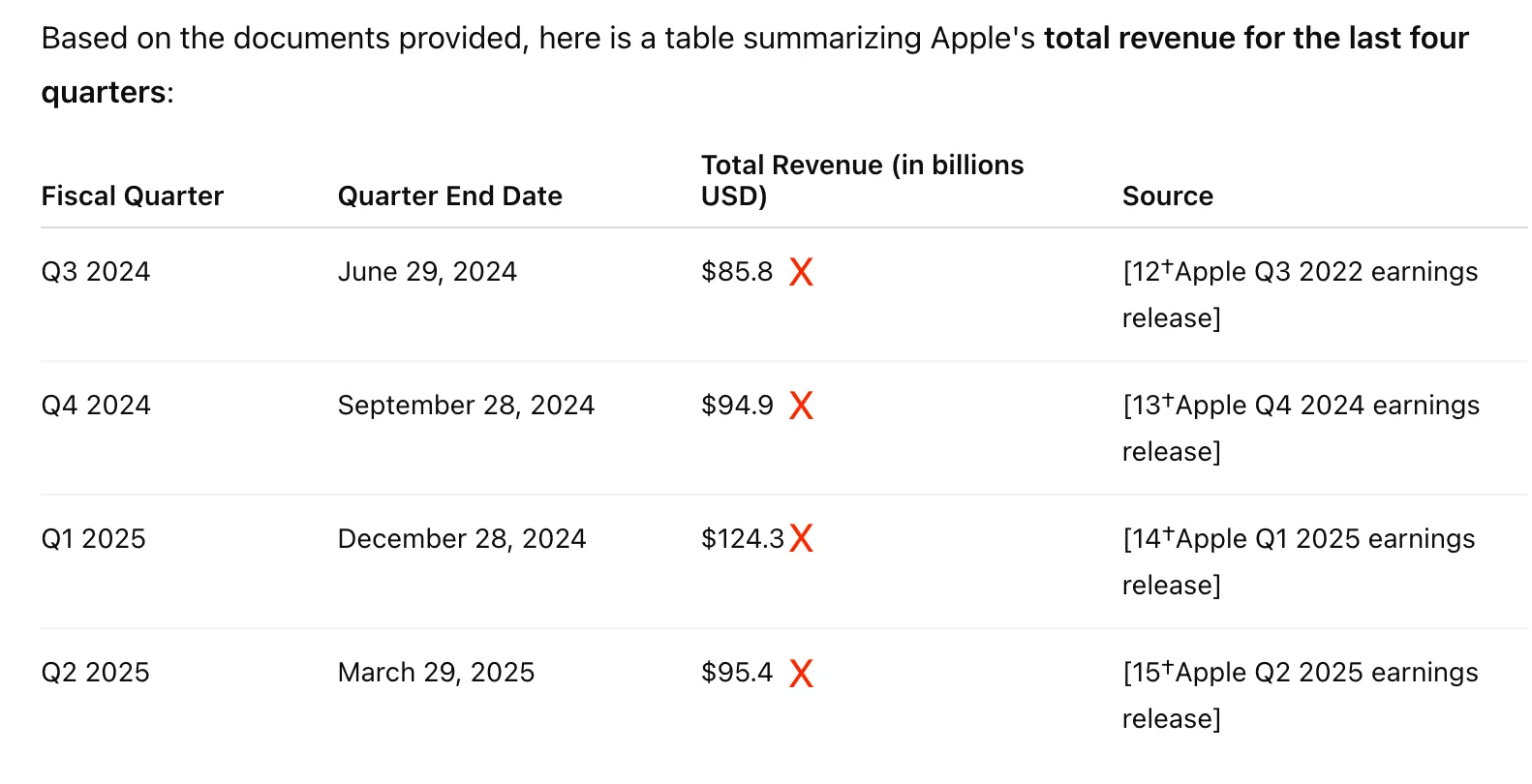

Hudson Labs Co-Analyst
The Co-Analyst results illustrate the platform’s multi-period guidance capabilities. See the results here.
5. All soft guidance from the Delta Airline’s earnings call
GPT-4o - web
GPT-4o successfully extracted a few verbatim forward looking statements. See full results here. However, here are some statements missing from GPT-4o output but present in the Co-Analyst:
- “Reflecting our confidence in the business, we are restoring financial guidance for the full year. We expect to deliver earnings per share of $5.25 to $6.25 and free cash flow of $3 billion to $4 billion.”
- “This free cash flow outlook is within our long-term target range and enables us to pay down $3 billion of debt this year while also returning cash to shareholders.”
- "Looking beyond 2025, I am confident in our ability to deliver financial performance that is consistent with the 3- to 5-year framework we outlined for you last fall."
- "We remain on track for full year remuneration of approximately $8 billion, providing durability to both earnings and cash flow."
- "For the September quarter, we expect revenue to be flat to up 4% year-over-year."
- "Our outlook reflects stable demand across both consumer and corporate segments with the midpoint similar to second quarter performance, excluding the impact from lapping the CrowdStrike caused outage.”
- "For the September quarter, we expect earnings of $1.25 to $1.75 per share and a 9% to 11% operating margin, and that's compared to 9.4% last year."
- "On the cost side, we continue to execute well and make progress on driving efficiency. We expect third quarter will mark our strongest cost performance of the year with nonfuel unit costs flat to down compared to 2024."
GPT-4o - uploads
GPT-4o did well in extracting guidance from the uploaded transcript. See full results here.
Hudson Labs Co-Analyst
Co-Analyst results were complete and accurate. See the results here.

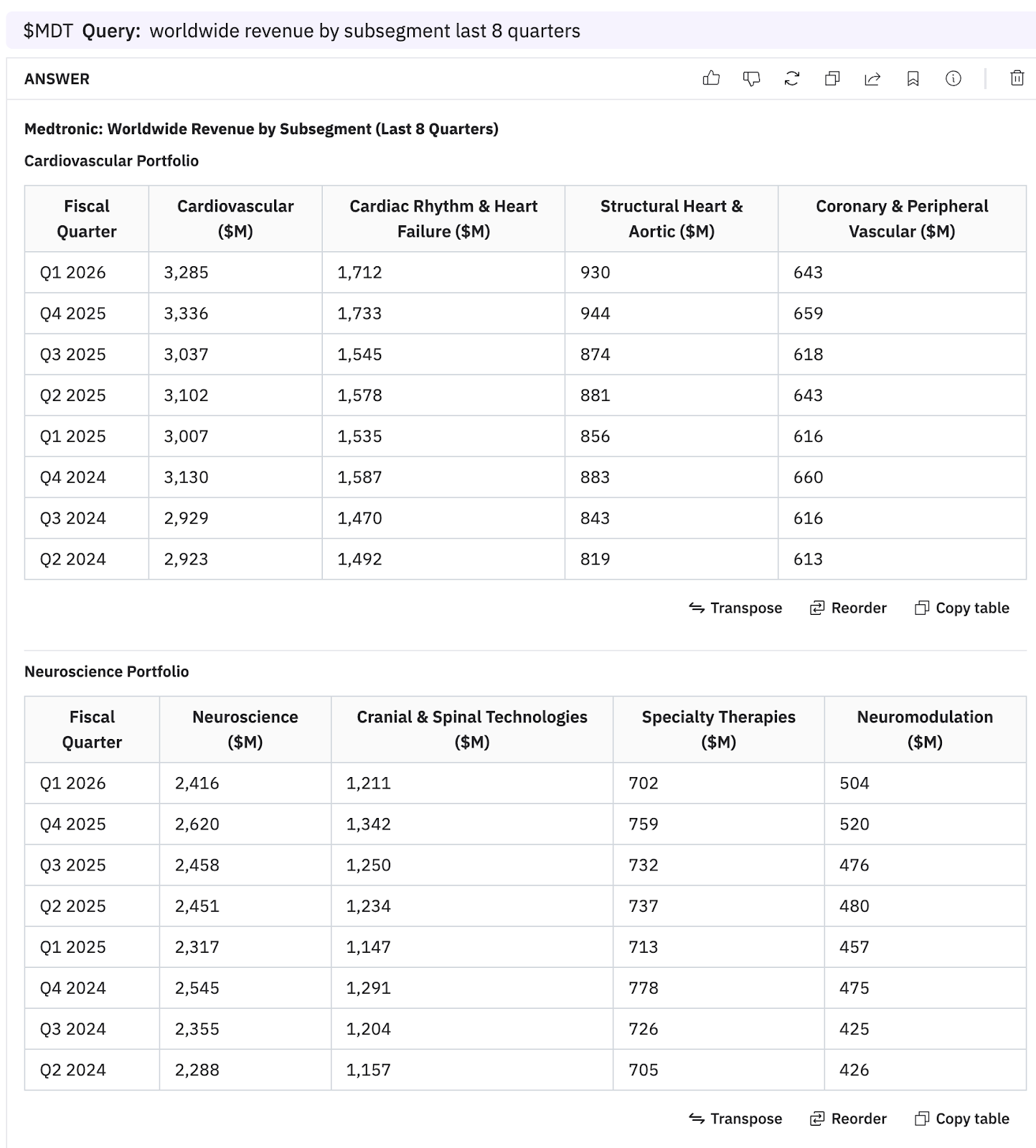
6. Medtronic revenue breakdown by subsegment
GPT-4o - web
GPT-4o web incorrectly provided 12-month revenue figures instead of quarterly figures and segments instead of subsegments.
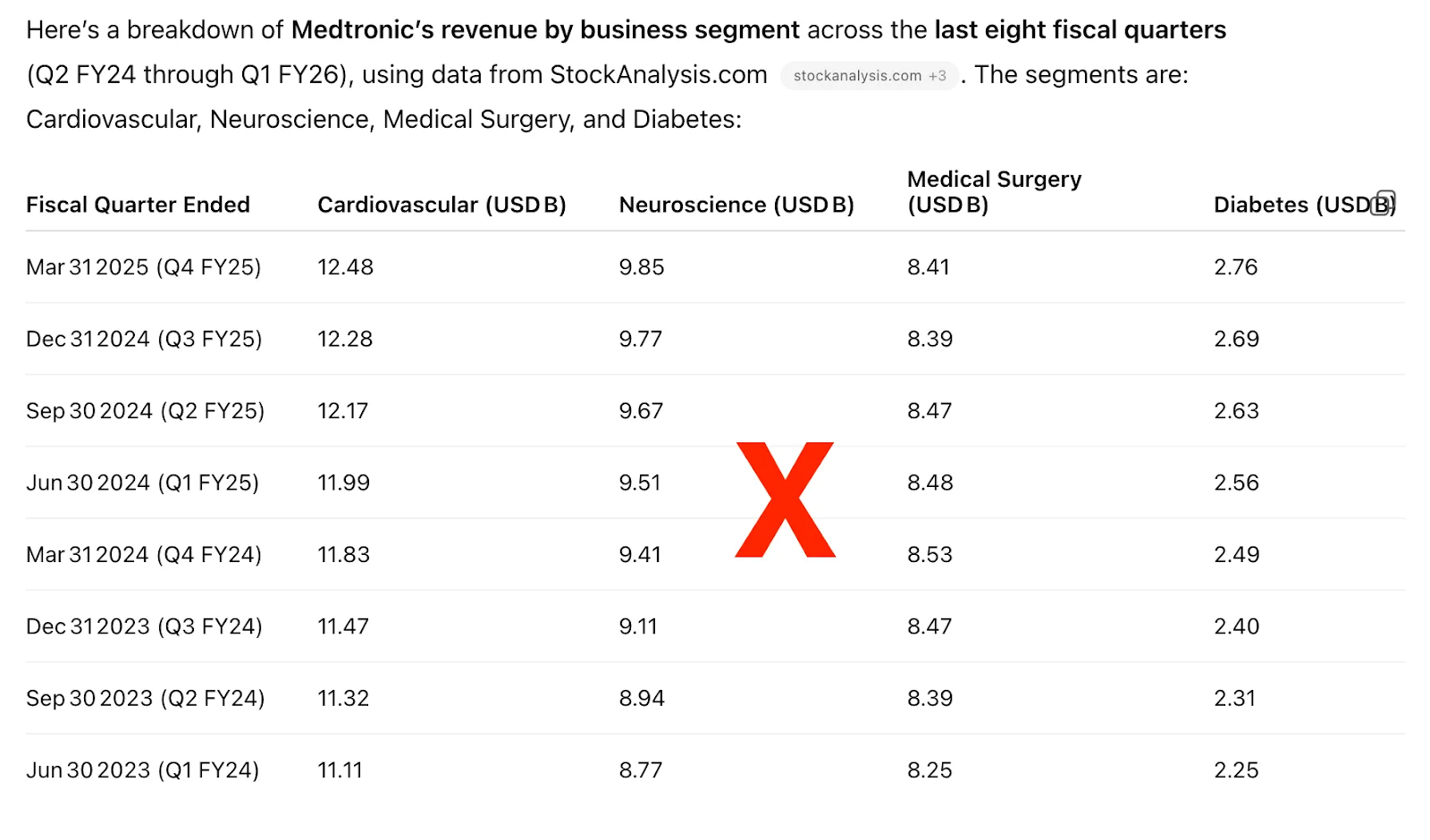
When explicitly asked for "quarterly revenue" breakdown by subsegment "(not segment)", GPT- 4o provided only qualitative commentary for each subsegment, in lieu of the specific figures. The specific numbers are disclosed. See the full results for both queries with GPT-4o web here.
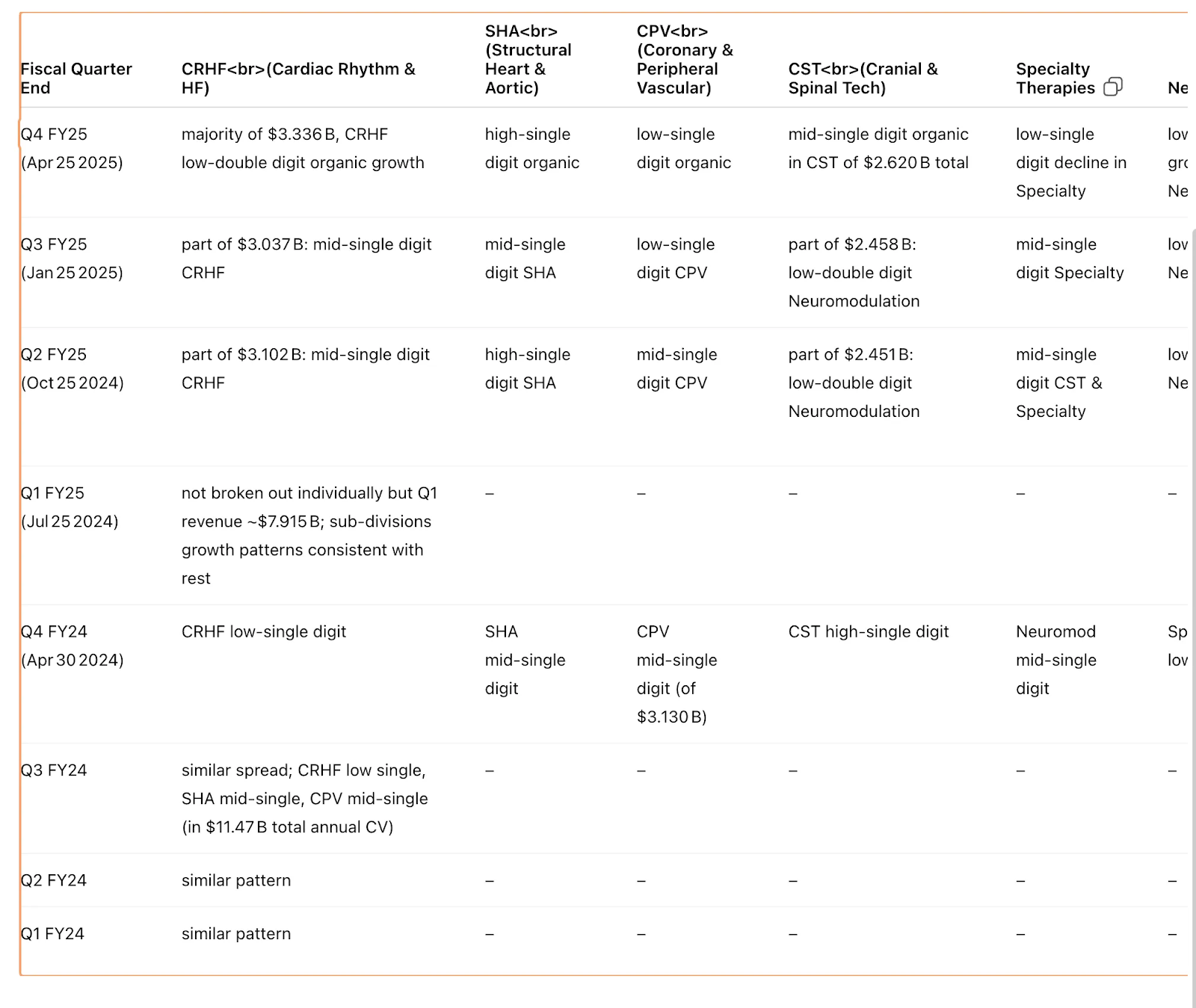
GPT-4o - uploads
We provided GPT-4o with PDFs of earnings releases and earnings call transcripts. Once again, GPT-4o focused on the qualitative commentary for each subsegment instead of getting the actual revenue figures. See full results here.
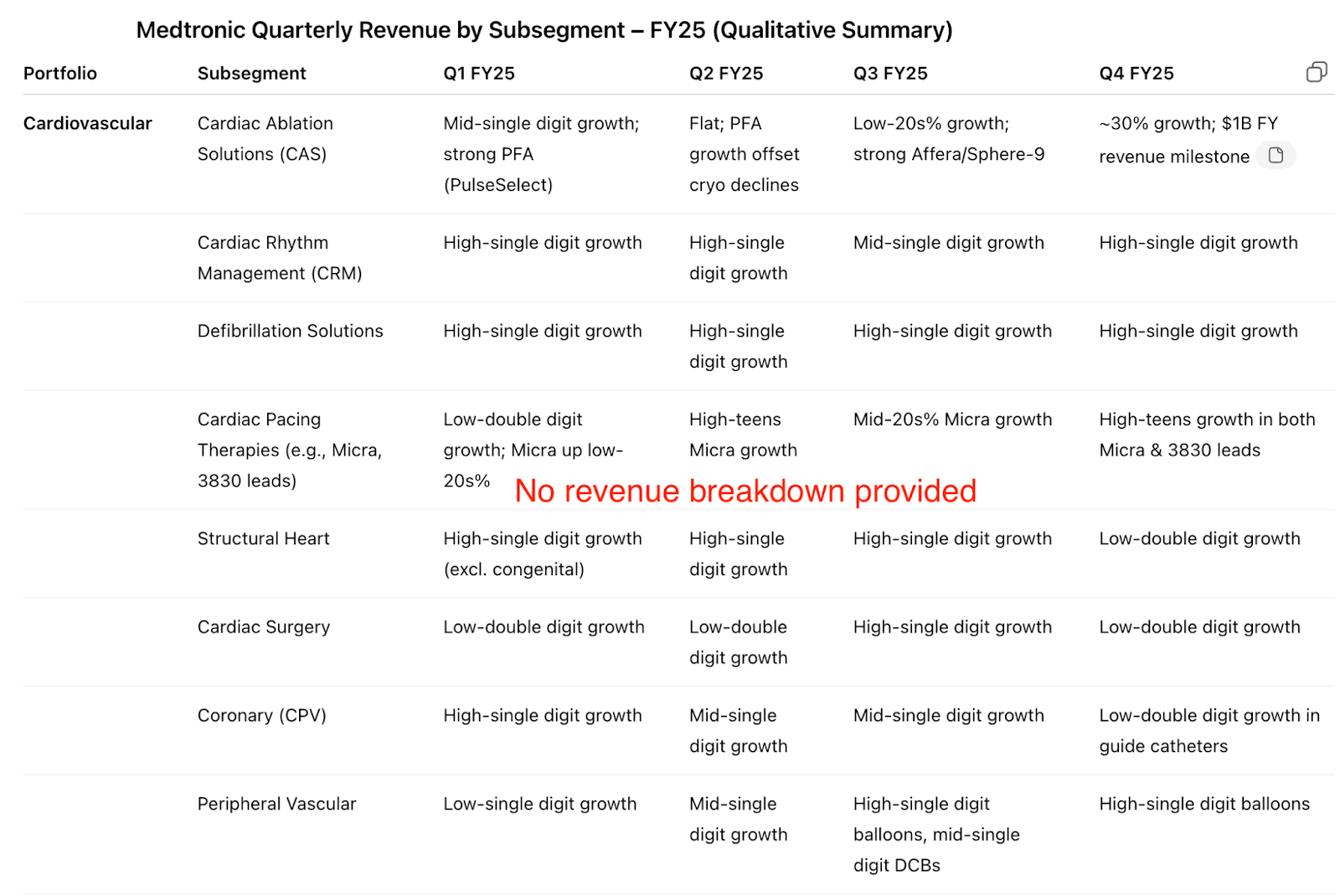
Hudson Labs Co-Analyst
This example demonstrates the Co-Analyst’s numeric focus. In this instance, the Co-Analyst unnecessarily includes segment details co-mingled with sub-segment data. However, all figures are precise and accurate. See the results here.
Conclusion
In investor-focused workflows, Hudson Labs Co-Analyst delivers greater accuracy, completeness, and consistency than Perplexity Pro. While generalist models remain competitive for creative or non-financial tasks, they show persistent weaknesses in numeric fidelity, guidance retrieval, and multi-period analysis. The Co-Analyst is purpose-built to close those gaps—requiring no prompt engineering and delivering reliable results out-of-the-box. Also see comparisons of the Co-Analyst to OpenAI's o3 and Perplexity.
Why not use FinanceBench?
A full comparison using FinanceBench queries is coming soon. However, FinanceBench does not test the areas that matter most to our users. It emphasizes mathematical accuracy, whereas the Co-Analyst avoids doing math to ensure traceability to source. FinanceBench lacks robust tests for guidance and multi-period retrieval. Like most benchmarks, it is easy to optimize for and rarely reflects real-world workflows.
Our analysis is limited in scope and based on internally selected queries—but it is designed to show how the tools perform in actual use. We encourage you to run your own queries via demo.


