We compare the Hudson Labs Co-Analyst to OpenAI’s o3 in the analysis below. o3 is OpenAI's reasoning model, designed to solve more complex, multi-step problems. The recently released GPT-5 is the evolution of the o3 model and in our initial tests, produced worse results. A full comparison is coming soon. Also see comparisons of the Co-Analyst to ChatGPT-4o and Perplexity.
The results demonstrate that Hudson Labs consistently outperforms o3 in investor-specific workflows—particularly in guidance extraction, numeric accuracy, and multi-period document analysis.
We do not claim general AI superiority—only targeted outperformance in investor-specific workflows. For creative tasks such as writing and style transfer, OpenAI models and other offerings from the big labs will be better suited.
Most financial AI tools are OpenAI wrappers
Many, if not most, finance-specific applications, including well-known brands, implement a wrapper on top of OpenAI. While this approach performs well for general tasks, its failure modes impact usability, particularly in financial workflows.
To be clear, this is not a critique of OpenAI’s model quality—on many general-purpose tasks, they outperform competitors. Hudson Labs, in fact, uses OpenAI models for select sub-tasks within the Co-Analyst. However, our architecture incorporates more than five other LLMs along with proprietary retrieval, source selection, and pre- and post-processing pipelines.
Our comparison to OpenAI's o3 model illustrates the differences between the Hudson Labs Co-Analyst and generalist systems (often OpenAI wrappers), which constitute most of the financial AI software on the market today.
Where the Hudson Labs Co-Analyst Excels:
Multi-period document analysis
The Co-Analyst excels when analyzing multiple long-form documents, such as earnings calls spanning more than four quarters. Its proprietary retrieval system scales better than generalist alternatives.
Guidance identification
Guidance often requires interpreting subtle context—sometimes from previous sentences or adjacent paragraphs. Our multi-model architecture ensures accurate extraction, even across periods.
Reliable results
The Co-Analyst minimizes hallucination through confidence-based decoding and post-processing. When information is unavailable, it returns “N/A” rather than fabricating results.
Numeric focus
Many AI systems provide general commentary but omit key figures. The Co-Analyst prioritizes numeric specificity and precision.
Under-covered names
Unlike models reliant on web search, the Co-Analyst maintains performance across the cap spectrum—from micro caps to mega caps.
The evaluation below tests the investor-specific areas where Hudson Labs specializes.
Primary benefits of Hudson Labs Co-Analyst versus o3:
No hallucination
The Co-Analyst minimizes hallucination through confidence-based decoding and post-processing. When information is unavailable, it returns “N/A” rather than fabricating results.
Latency & efficiency
Queries that take less than 30 seconds to run using the Hudson Labs Co-Analyst can take up to 7 minutes using o3.
Guidance identification
Even sophisticated models like o3 struggle with subtle timing cues about future tense. This is why many AI models cannot reliably identify guidance, particularly soft guidance and qualitative outlook statements. Hudson Labs specializes in guidance identification.
Information access
The Hudson Labs Co-Analyst has direct, timely access to call transcripts, presentations and investor news. o3 is restricted to web-based results. Not all relevant information is indexed on Google plus there is a delay in indexing the information that is available.
Methodology
We compare the Co-Analyst to o3 using targeted queries that reflect Hudson Labs’ core strengths: multi-period analysis, guidance extraction, numeric precision, and reliability.
Tests
1. Apple Guidance
o3
When asking for Apple’s revenue guidance for the last 8 quarters, it took o3 7 minutes to get a response. That is even considering how much readily available information there is on Apple for web-based query searches. o3 also said that Apple did not provide a quantitative revenue guidance in the Q4 call. However, it missed that the management provided qualitative guidance, expecting revenue to be similar to last year despite 1 less week in the quarter. This was noted in the Co-Analyst answer below. See full results here.
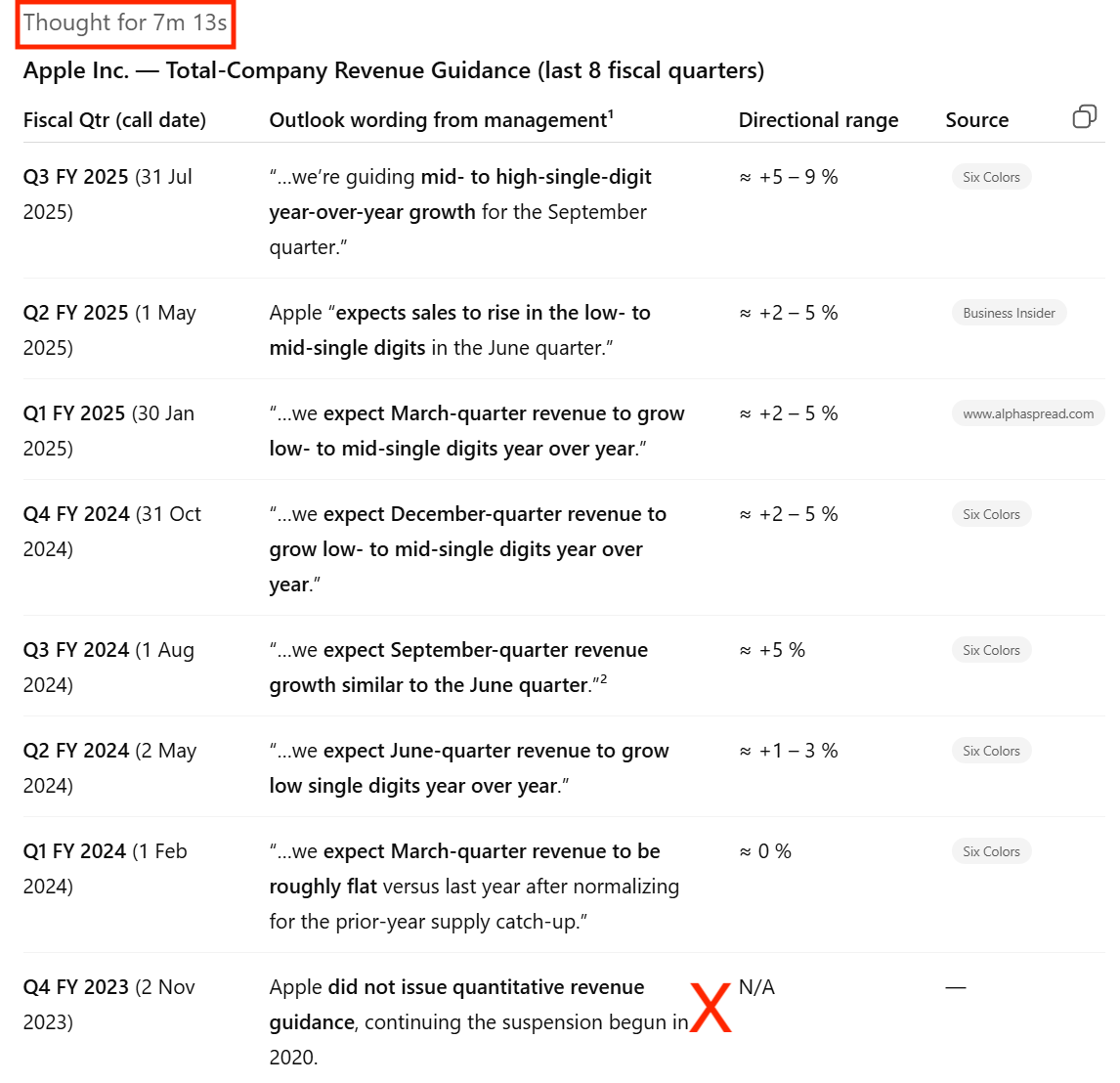
Co-Analyst
The Co-analyst pulled the revenue guidance in less than 30 seconds. Here.
2. Soft guidance - Delta Airlines
o3 missed several guidance statements that were picked up by the Co-Analyst:
“Our goal is to have about 20% [of domestic network] by the end of the year [using Fetcherr’s AI-enhanced pricing solutions].”
"We are committed to shareholder returns. We recently announced a 25% increase to our quarterly dividend starting in the third quarter, bringing our annual commitment to approximately $500 million.”
“fully anticipate over the course of the 3 years, we will exercise that for share repurchases.”
"We should have almost all of our crowding issues [in Sky Clubs] solved in the next 18 to 24 months.”
"Potentially a low single-digit cash taxpayer next year, and then that would march up over a longer-term period, multiple year period to kind of mid-teens is how we see it today.”
“look ahead to 2026, we're incorporating these evolving seasonal patterns into our international network planning to align with customer preferences and travel behavior.”
"We're working all those levers and point feel confident in the $3 billion to $4 billion range [free cash flow].”
"It could be positive this year. I'm not writing off that it could not be -- I think we have a good shot of it becoming positive or at least neutral by the third quarter or fourth quarter of this year [main cabin revenue].”
"We hope that template [U.S.-U.K. trade agreement] will continue in future negotiations."
"We are heartened by the U.K., U.S. acknowledgment in the recent trade agreement that the 1979 Aviation Act where there would be no tariffs and on a reciprocal basis would be honored."
"We’re not planning on paying any tariffs for aircraft deliveries.”
See the full o3 answer here. And the Co–analyst output here.

3. Steve Madden china sourcing
o3
Correctly identified figures, but it gave multiple different output sources for the same figure. See the o3 output here.
Co-Analyst
The Co-Analyst delivered precise, cited figures with no hallucination and returned “N/A” where data was absent. See the full Co-Analyst result here.
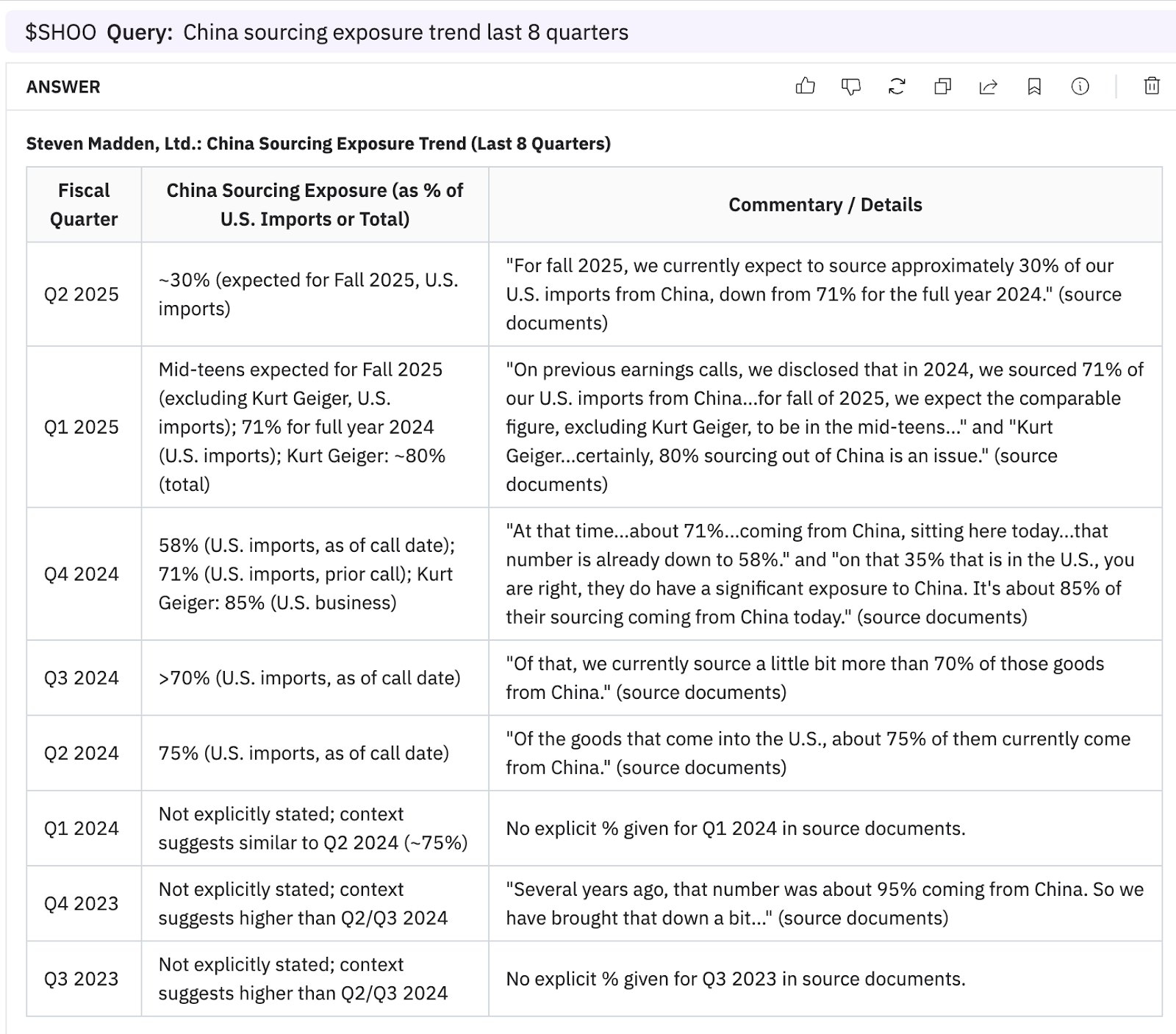
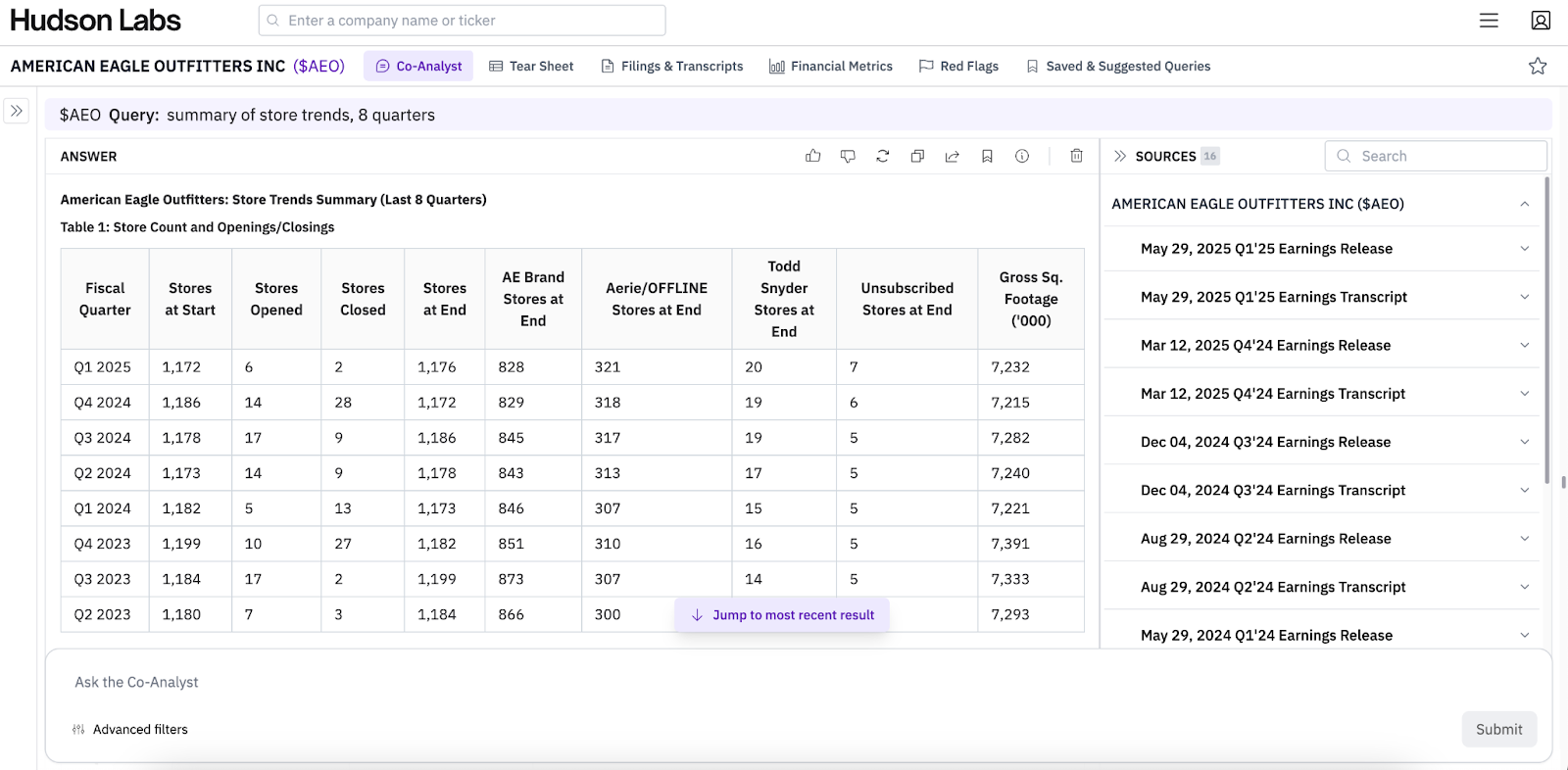
4. American Eagle store trends
o3
o3 for 6.5 minutes only to give us incorrect (hallucinated) numbers for Q4’24, Q1’24 and Q3’23 that looked highly plausible. See the full answer here.
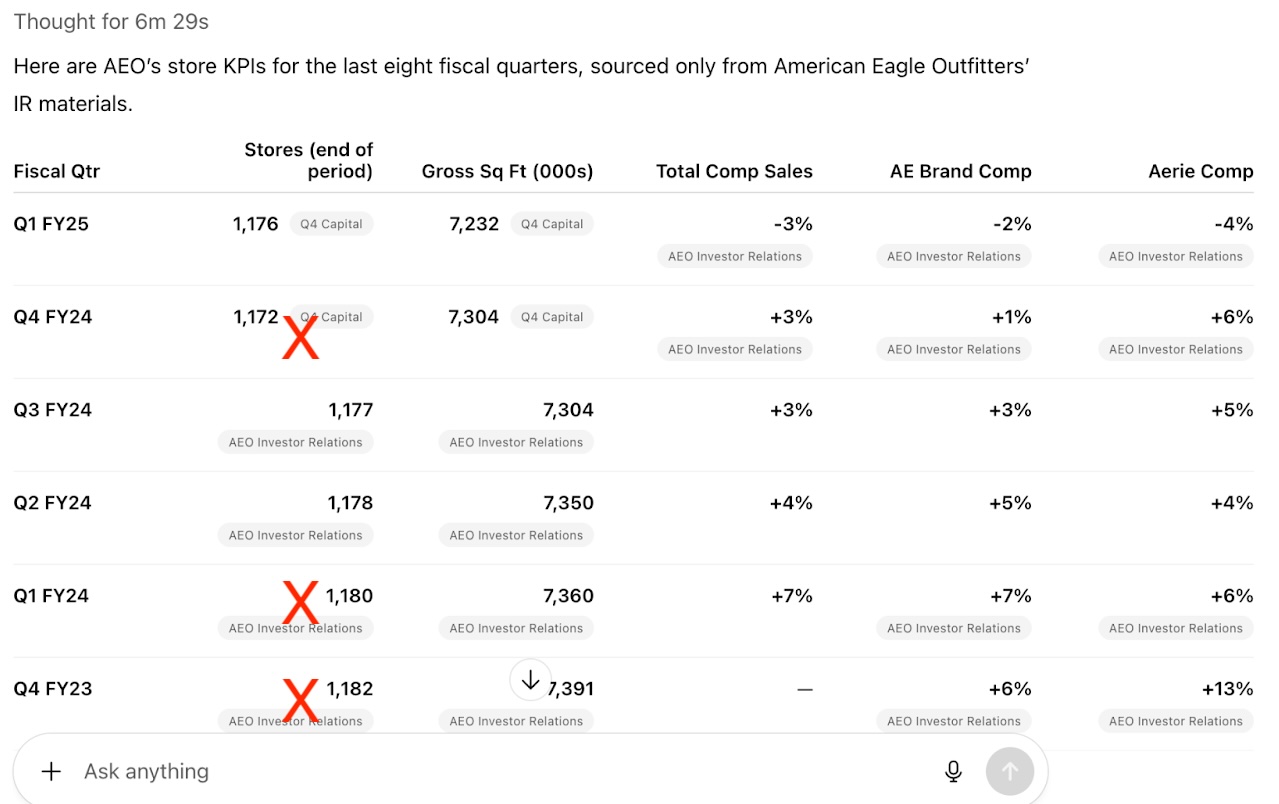
Here'e's the correct figure for number of stores at the end of Q4 2024:
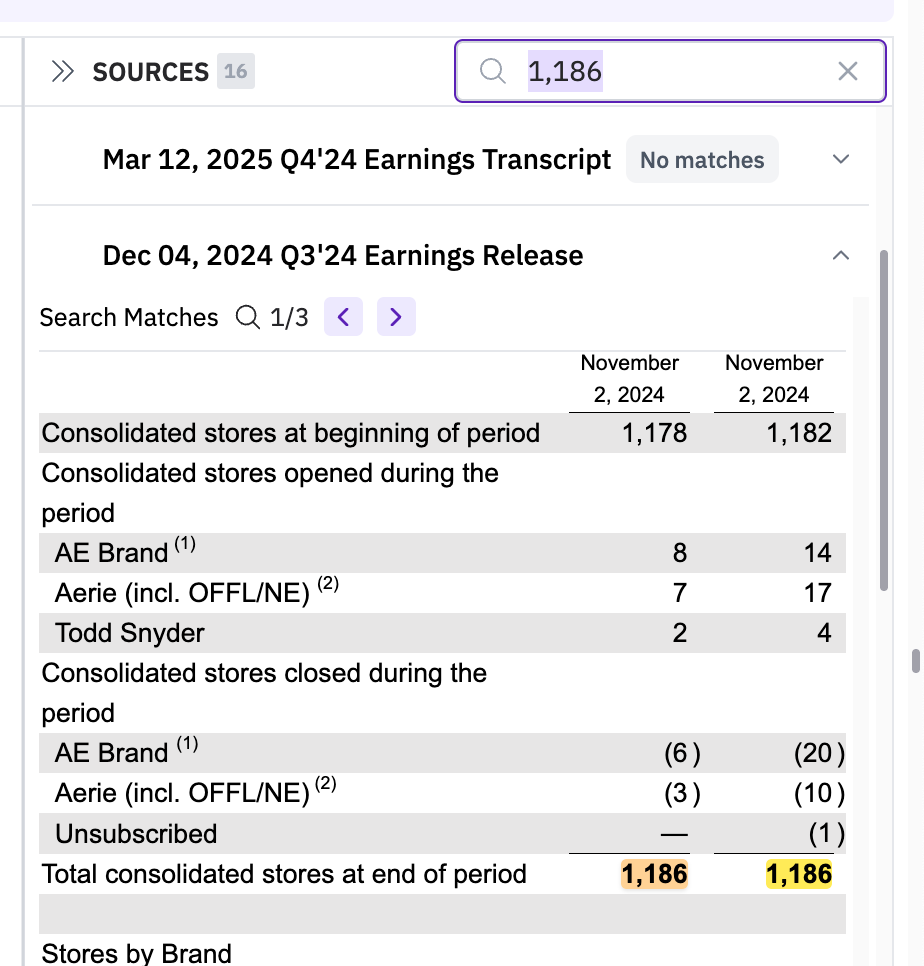
Co-Analyst
With a proprietary retrieval system, the Co-analyst gives the response in <30 seconds, with complete and accurate figures. Read the full response here.
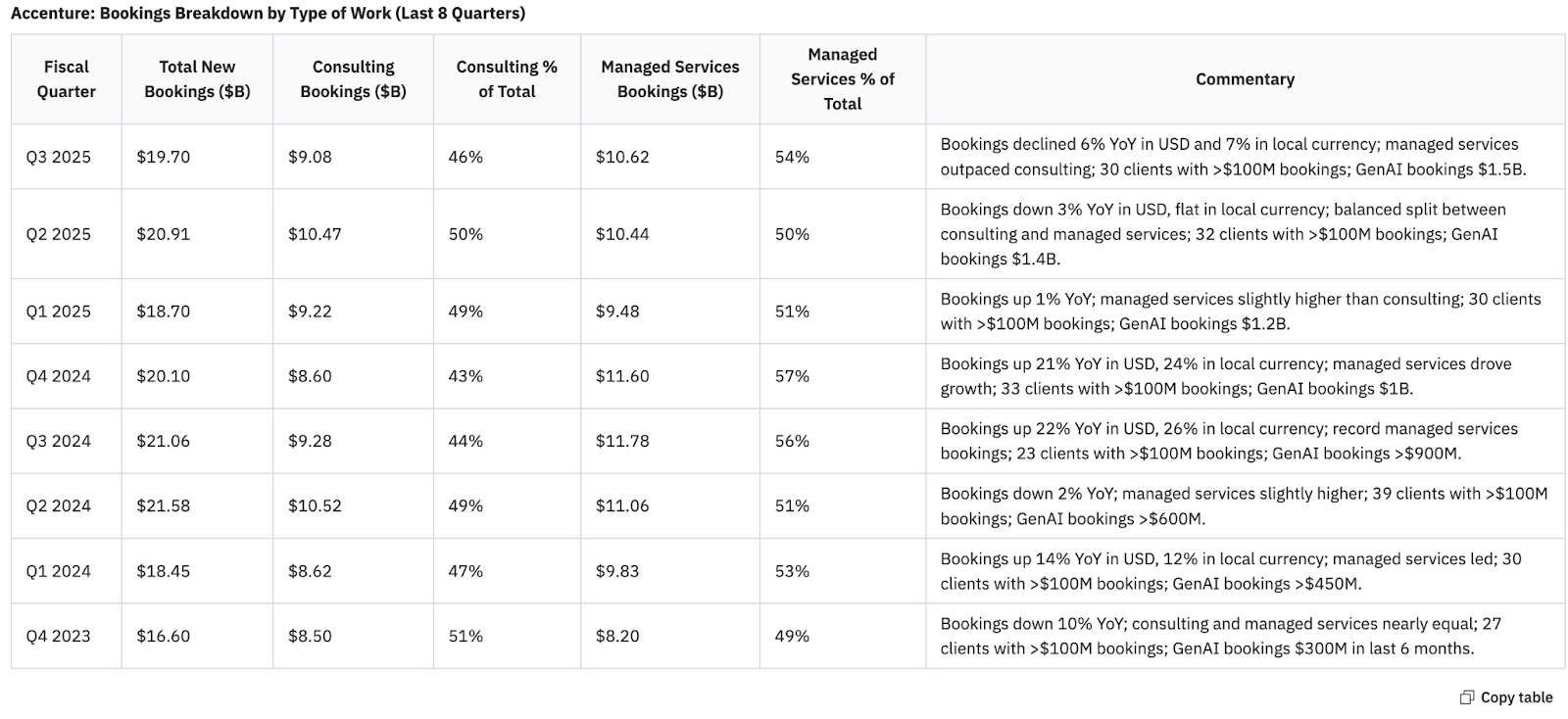
5. Accenture bookings trends
o3
o3 pulled figures for all periods that were not entirely wrong, however, with inconsistent sourcing between earnings releases and transcripts, it sometimes pulls fully reported numbers, sometimes it pulls rounded numbers from opening remarks and then puts them in the same table. Full query here.
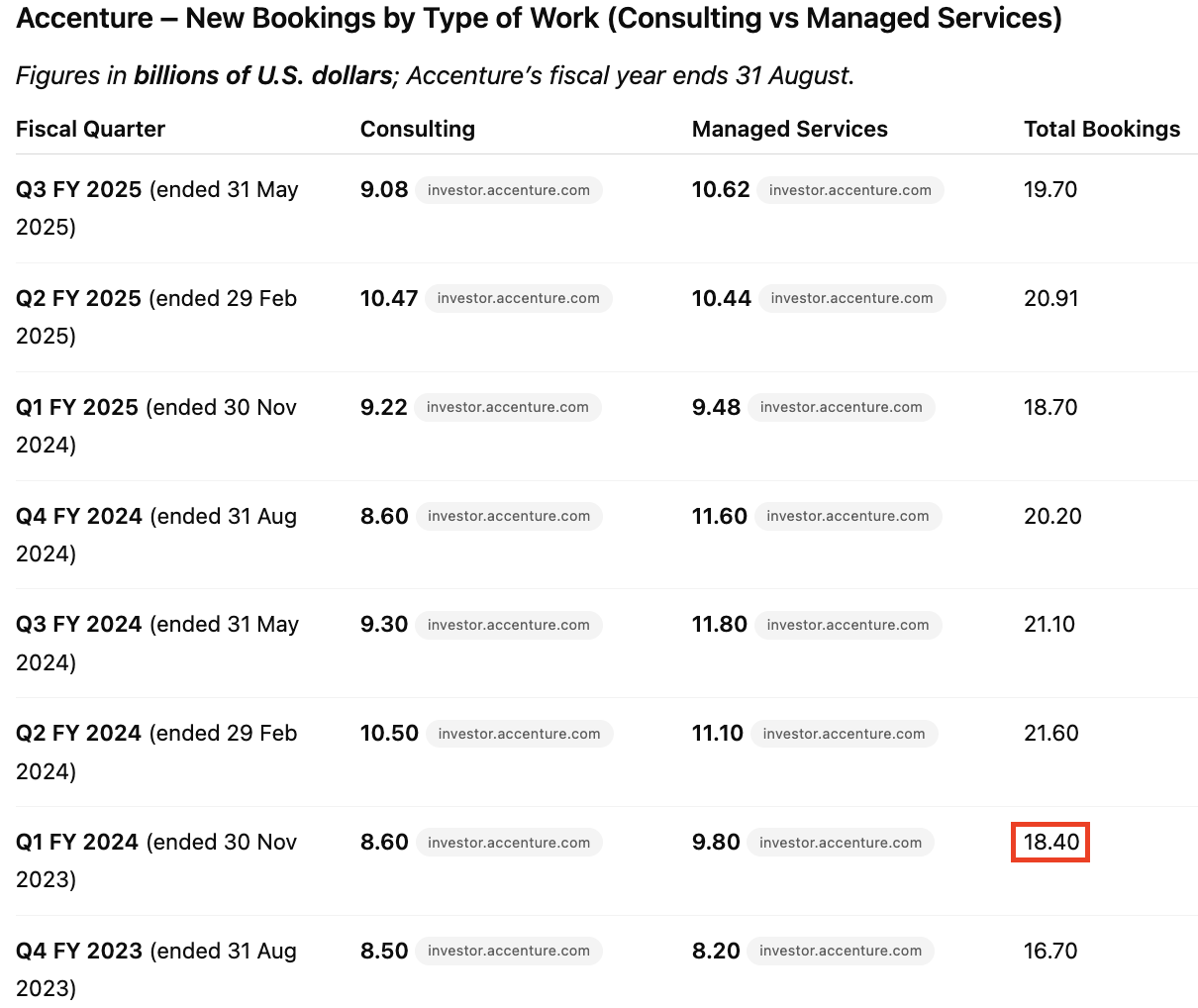
Actual reported figure from citation in Co-analyst below.

Co-Analyst
The Co-Analyst provides detailed, complete and precise results for a full 8 quarters. Full response here.
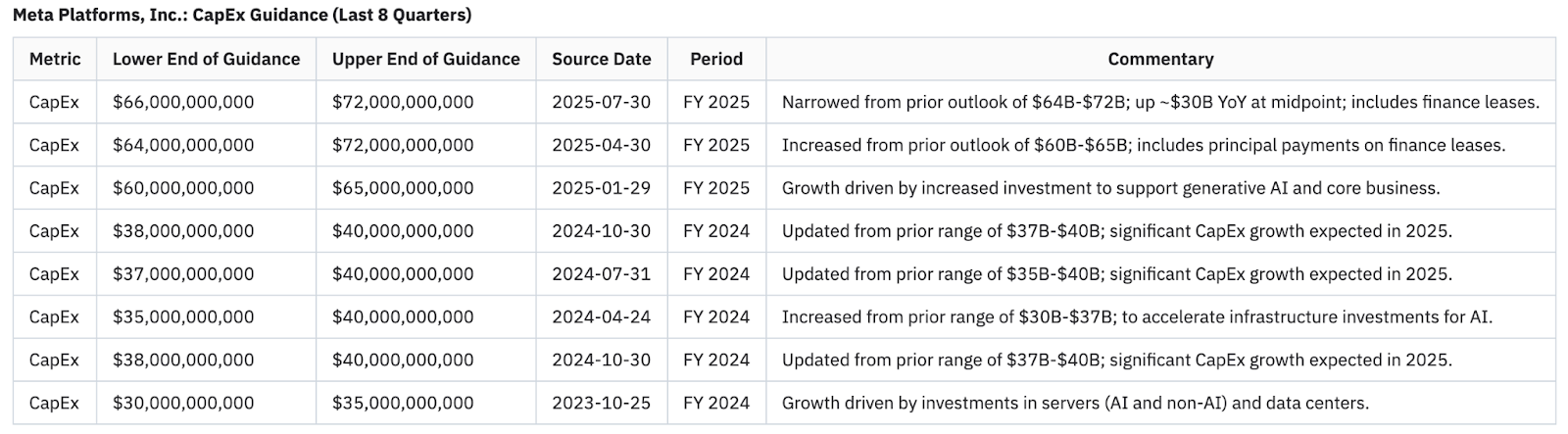
6. Meta Capex guidance over time
o3
When asking for Capex guidance, o3 did a good job on more recent guidance, however it is not pulling numbers from longer periods, where it stated there was no numerical range given, dispute there being one right in the quote beside it. See the full response here.
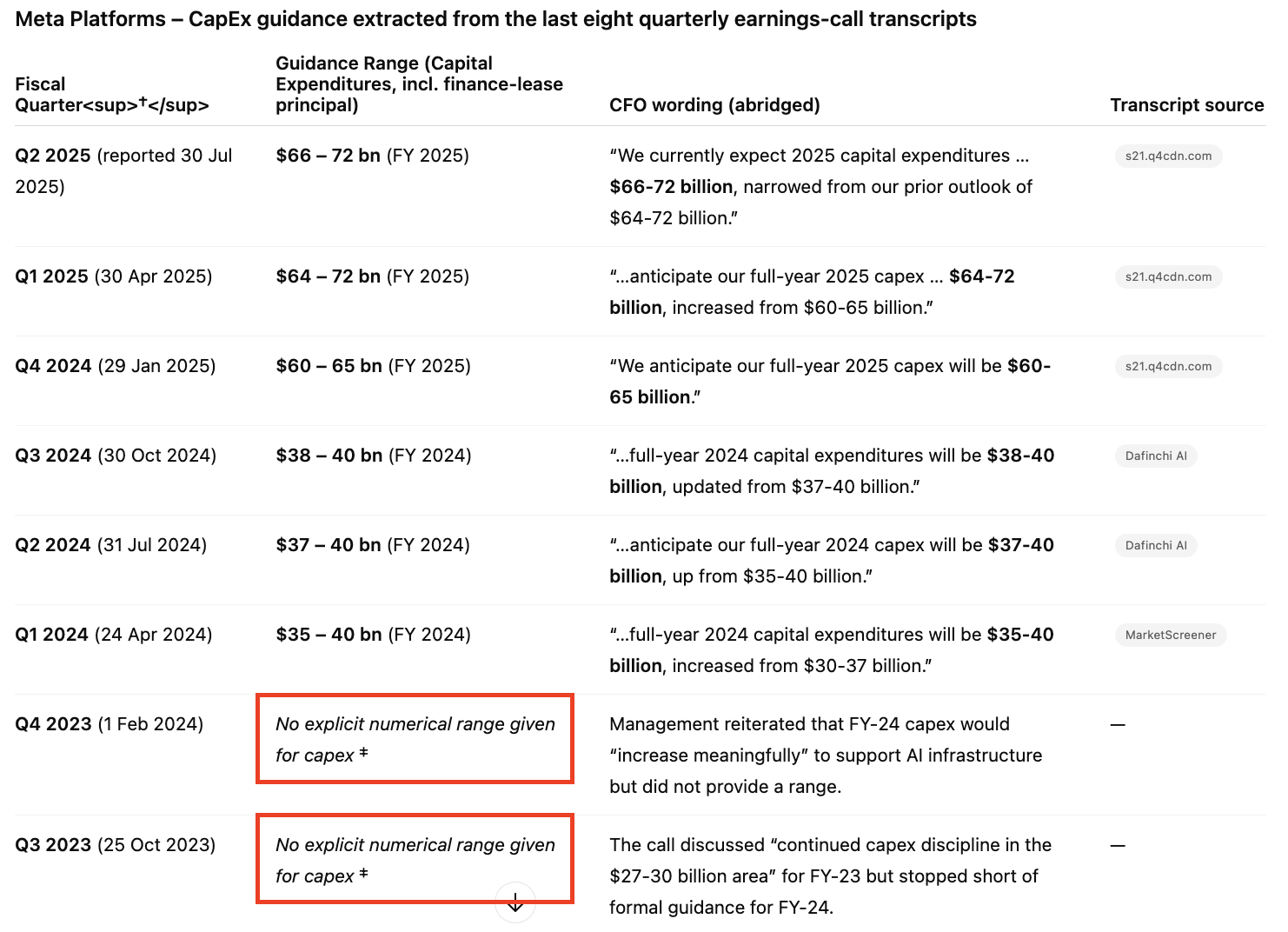
Co-Analyst
The Co-analyst correctly pulls all periods here.
Conclusion
Hudson Labs delivers where it matters most: precision, reliability, and relevance in investor-specific workflows. While general-purpose models excel in creative and open-ended tasks, they fall short on accuracy, numeric fidelity, and multi-period analysis. Also see comparisons of the Co-Analyst to ChatGPT-4o and Perplexity.
If you have held back from integrating AI due to concerns over hallucination, prompt engineering, or inconsistent results, Hudson Labs is purpose-built to solve those problems—out of the box.
Why not use FinanceBench?
A full comparison using FinanceBench queries is coming soon. However, FinanceBench does not test the areas that matter most to our users. It emphasizes mathematical accuracy, whereas the Co-Analyst avoids doing math to ensure traceability to source. FinanceBench lacks robust tests for guidance and multi-period retrieval. Like most benchmarks, it is easy to optimize for and rarely reflects real-world workflows.
Our analysis is designed to show how the tools perform in actual use. We encourage you to run your own queries via demo.


